이번 포스터에서는 Segmentation 모델인 Mask-RCNN(Mask Region Convolution Neural Network)에 대해 알아보자. Mask-RCNN은 Mask-RCNN이라는 논문에서 발표되었다. 논문에 대한 자세한 리뷰는 여기에서 확인할 수 있다. 2017년에 발표된 이 논문은 그 당시에 SOTA모델들의 성능보다 우수했다.
Mask-RCNN 개요
Mask-RCNN은 매우 간단하면서도 flexsible하며 좋은 성능을 보이는 Instance Segmantation모델이다. Semantic의 경우 물체가 같은 class면 같은 분류로 묶지만 Instance의 경우 같은 class 안에서도 서로를 다른 객체로 인식하는 기술이다. Object Detection분야에서 좋은 성능을 보인 Faster-RCNN모델에서 약간의 overhead만 추가해 Segmemtation을 구현했다.
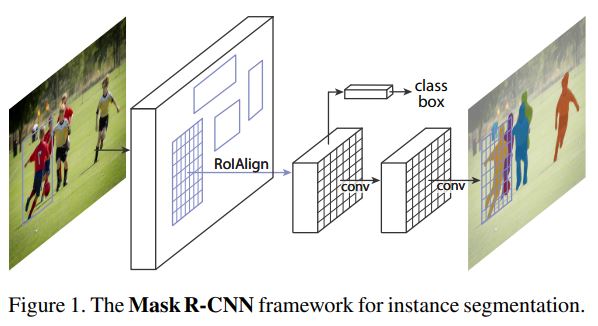
이 모델이 발표될 당시에 Segmentation에서 좋은 성능을 보인 FCNs모델과 합쳐 논문에서는 다양한 ablation을 통해 여러 조합들의 성능을 평가했고, $AP_{50}$를 기준으로 최대 60.0포인트까지 기록했다. 또한 기존 Faster-RCNN 모델에서 사용하던 RoIPool을 RoIAlign으로 변경하면서 성능에 긍정적인 영향을 주었다.
Mask-RCNN의 특징은 다음과 같다.
- Backbone모델로 ResNet 사용
- Feature Pyramid Network(FPN) 추가
- Object Detection모델인 Faster-RCNN 사용
- Segmentation을 위한 Mask branch 추가
- RoIPool을 RoIAlign으로 대체
- Human pose estimation으로 활용
Mask-RCNN 구조
Mask-RCNN의 구조를 보면 다음과 같다.
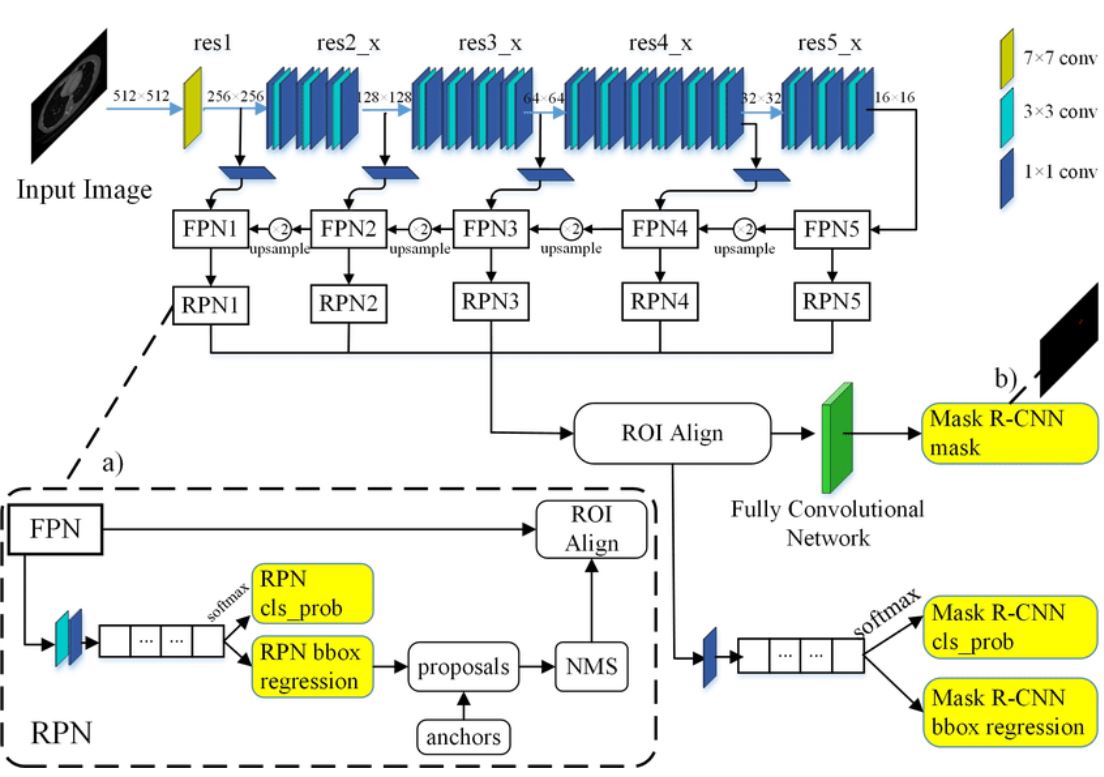
Mask-RCNN의 Forward과정은 다음과 같다.(임의의 Input size N에 대해)
- Input 이미지가 Backbone인 ResNet을 통과하여 각 layer별로 feature map을 추출한다.(C1, C2, C4, C4, C5)
- Layer별로 추출된 feature map을 각각 FPN을 통과시킨다.(P1, P2, P3, P4, P5)
- FPN을 통과시킨 output을 각각 Region Proposal Network(RPN)에 적용시켜 bbox regression과 objectness score를 산출한다.
- 산출된 bbox의 좌표를 원본 input 이미지에 Projection하여 Anchor box를 생선한다.
- Non-Max Suppression(NMS)를 적용해 objectness의 score를 기준으로 상위 100개의 Anchor box만 선택한다.
- 최종 후보인 Anchor box에 PoolAlign을 적용해 모두 동일한 size로 변환한다.
- PoolAlign가 적용된 feature에 (classification & bbox regression)와 (Mask prediction)을 각각 독립적으로 적용한다.
최종적으로 RoI 100개에 대한 C(class개수)개의 Mask와 C개의 bbox 좌표, C개의 class score가 출력된다.
시각자료는 많을수록 좋으니 아래는 Mask-RCNN과정의 다른 이미지이다.
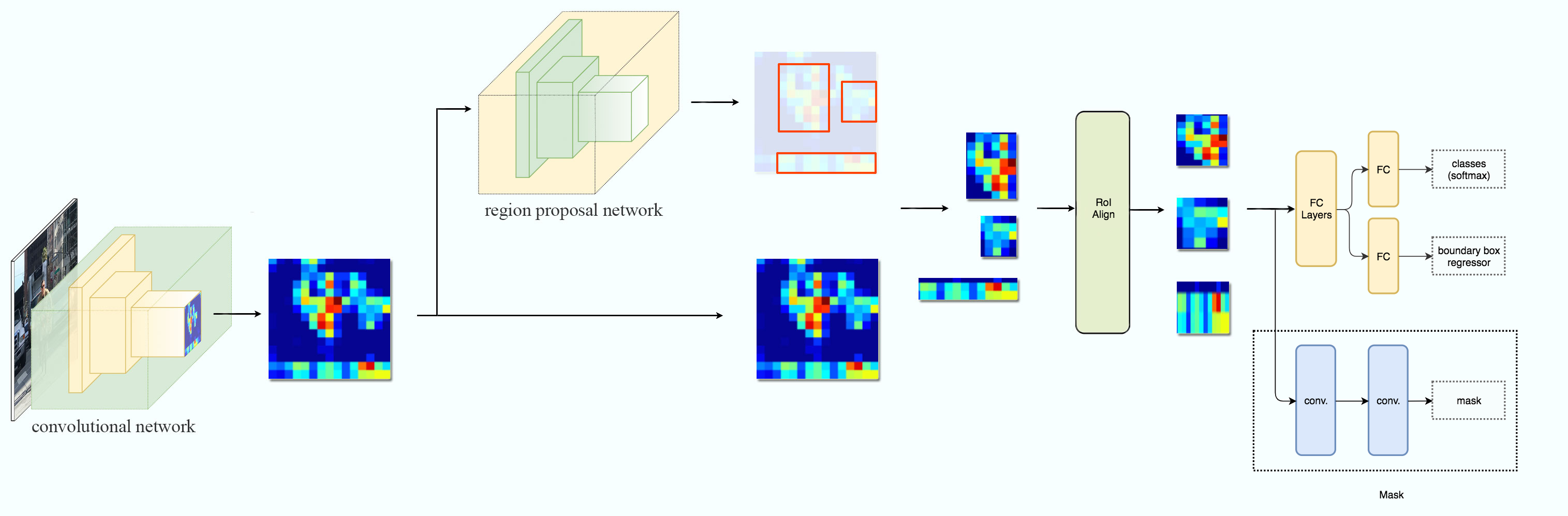
이제 Mask-RCNN의 구조를 하나씩 찢어보며 특징에 대해 자세히 알아보자.
Faster-RCNN
Mask-RCNN를 알기 위해서는 Faster-RCNN의 구조를 알고 있어야 한다. 왜냐하면 Faster-RCNN에서 아주 작은 기능인 Mask 예측 Layer만 추가한 모델이 Mask-RCNN이기 때문이다. Faster-RCNN은 Object Detection테스크에서 사용된 모델이고, 다음과 같이 구성되어 있다.
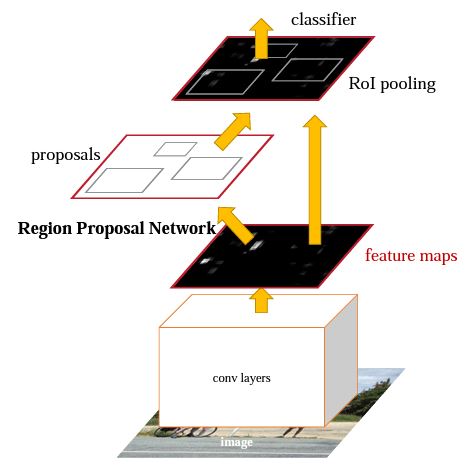
RCNN 시리즈에서 3번째로 탄생한 모델이다. RCNN과 fast-RCNN을 거쳐 Faster-RCNN이 탄생했는데, 이름에서도 알 수 있듯이 앞에 2개의 모델보다 빠르고 정확한 모델이다. Input 이미지에서 Conv Layer를 통과해 Feature를 추출하고, Region Proposals를 뽑아 classification과 bounding box regression을 하는 것은 모두 동일하다. 하지만 faster-rcnn은 그 과정에서 여러 테크닉이 추가되었다.
- Region Proposals를 생성할 때 Selective Search를 사용하지 않고 Region Proposal Network를 사용한다.
- Fast-RCNN에서 사용했던 RoIPooling Layer의 발전된 버젼인 RoIAlignPooling Layer를 사용한다.
Fatser-RCNN의 Forward과정은 다음과 같다.
- Input Image에서 Conv Layer를 거쳐 feature map을 추출한다.
- 추출된 feature map는 Region Proposals를 생성하는 RPN에서 사용되고, 또한 이후에 RoIAlign을 위해 저장된다.
- RPN으로부터 Region Proposals에 대한 보정된 bbox 좌표값과 objectness(물체의 유무)가 산출된다.
- 산출된 bbox 좌료값 중 특정 objectness점수를 넘은 bbox만 선택된다.
- RPN을 통해 선택된 생성된 bbox 좌표값을 (2)번에서 추출했던 Feature Map에 Projection시켜 Region Proposals(Region of Interset, RoI)를 생성한다.
- RoI에 RoIAlignPooling Layer를 적용해서 모두 동일한 Size로 변환한다.
- 이후에 FC Layer를 거쳐 classification과 bbox regression을 실시한다.
더욱 자세한 얘기는 Mask-RCNN와는 크게 연관성이 없기 때문에 따로 포스팅을 할 예정이다.
Mask Branch
Mask-RCNN은 Segmentation 테스크에서 사용되는 모델이다. 따라서 Detection만 가능한 Faster-RCNN에 Segmentation을 할 수 있도록 Mask-Branch를 추가했다.
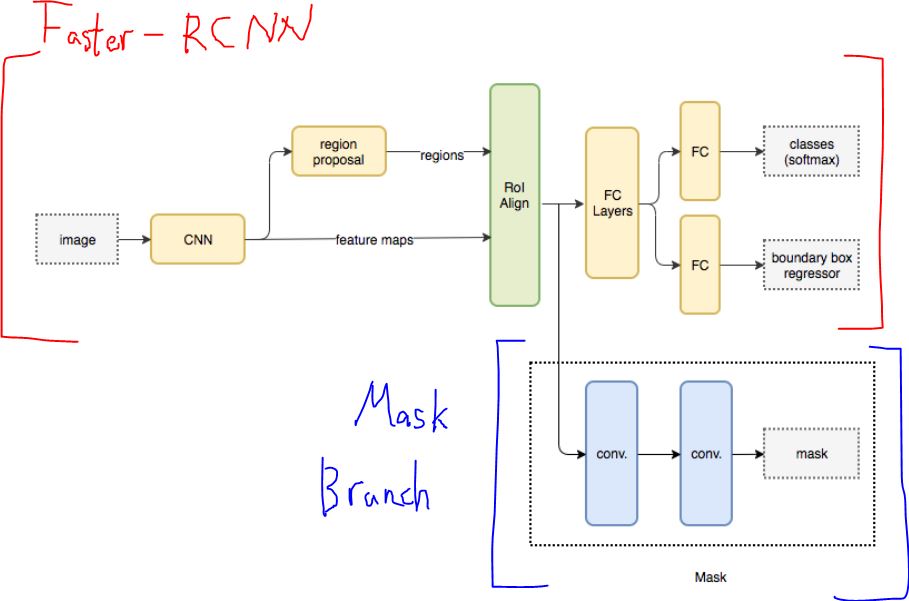
논문에서 Fatser-RCNN에 작은 overhead만 추가해서 Mask-RCNN을 만들었다고 하는데, Mask Branch가 바로 그 overhead에 해당한다. RoIAlignPooling Layer단계 이후를 Mask-RCNN head라고 부르는데, Faster-RCNN head에서 Mask-Branch가 추가된 구조라고 할 수 있다. Mask Branch는 Semantic Segmentation모델인 FCNs와 매우 유사한 형태를 하고 있다.
Mask Branch의 경우 classification, bounding box regression과는 다르게 FC Layer를 사용하지 않고 Conv를 사용했다. Segmentation의 경우 픽셀 단위까지 예측을 해야하기 때문에 더 정밀한 데이터를 유지해주기 위해 공간정보를 최대한 보존하는 Conv Layer를 사용했다.
Head Architecture
Mask-RCNN Head의 구조는 Feature Extraction부분에서 사용한 Backbone의 종류에 따라 다르게 형성된다. 아래는 2개의 Backbone에 대한 차이를 나타낸 사진이다.(Backbone의 종류는 뒤에서 다룬다.)
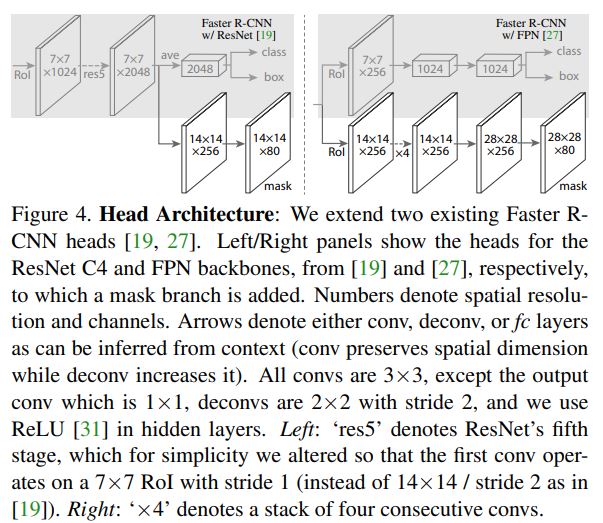
왼쪽의 경우 ResNet-C4, 오른쪽의 경우 ResNet-FPN을 Backbone으로 사용했다. 공통적으로는 RoIAlign을 통과한 RoI의 크기가 7x7이고, mask의 크기는 28x28 또는 14x14이기 때문에 Deconv이 필요하다. 논문에서는 Deconv 시 2x2 Filter와 2 stride를 사용했다고 한다.
Mask Prediction
FCNs와 비슷한 구조를 가지고 있지만, 가장 큰 차이점은 classification과 Mask Prediction의 분리 여부이다. 아래 그림은 FCNs와 Mask-RCNN의 mask-prediction부분이다.
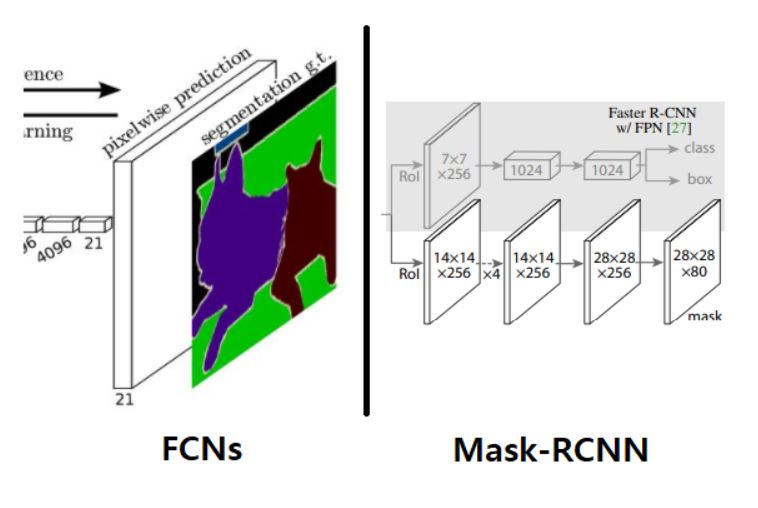
위 그림에 output을 예로 들면, FCNs의 경우 Mask가 21개의 channel이 나왔을 때 모든 채널에 대해 pixel-wise하게 Softmax를 적용해 각 픽셀별로 1개의 class로 예측한다. 최종적으로 나오는 Mask는 1개의 channel이며 해당 channel의 픽셀값은 class에 해당한다. 즉, classification과 Mask Prediction이 동시에 수행되었다고 할 수 있다.
하지만 Mask-RCNN의 경우 그림에서도 알 수 있듯이 classification과 Mask Prediction이 서로 분리되어있다. Mask가 80개가 나온 것을 알 수 있는데, 이것은 class의 개수만큼 출력이 된 것이다. 그리고 각 class의 channel은 0과 1로 이루어진 binary mask이다. 따라서 각 channel마다 물체가 독립적으로 존재하고, 배경과 물체가 0과 1로 구분되어있다. Mask-RCNN의 mask prediction절차는 다음과 같다.
- classification를 통해 RoI의 class를 확정
- class가 확정되면 class개의 Mask 중 class번째에 해당하는 Mask channel만 가져온다.
- 선택된 class번째 mask channel에 bbox를 overlap해서 겹치는 부분을 출력 - 솔직히 이 부분이 맞는지 모르겠음
- 학습 시에는 정답 mask와 class번째 Mask channel만 loss를 구한다.(나머지는 사용x)
FCNs처럼 같이 하는 것 보다 분리해서 할 때 성능이 더 좋다고 ablation study를 통해 증명했다.
Input Size
Inference
논문에서 COCO datasets으로 Inference진행 시 어떤 size로 input할건지 언급이 없었다. 하지만 CityScopes데이터셋에서는 1024로 통일한다고 한다. 또란 깃허브에서 언급하길 학습 시 1 batch에 여러 이미지를 사용하기 위해 같은 size로 통일해줬다고 언급했다. 따라서 COCO datasets도 모든 사진을 1024x1024로 통일한다고 가정하자. 물론 어느 Size든 Inference하는데 상관은 없다.
Training
하지만 학습 시 Input의 size는 명시되어있다. 이미지 size의 짧은 edge를 기준으로 800pixel로 통일을 한다. Keypoints와 CityScopes dataset에 적용한 input의 특징을 보면 train과 inference의 input size가 다르다. Overfit을 방지하기 위해 다른 size를 사용했다고 하는데, COCO dataset에도 동일하게 적용한다면 train과 inference가 달라야 하지 않을까? 의문이 투성이긴 하다…
BackBone
여러 model들간의 speed/accuracy관계를 보여준 논문에서 깊고 복자할수록 성능이 좋다는 것을 보였다. Mask-RCNN논문에도 다양한 backbone을 실험해서 이러한 결과를 도출했다.
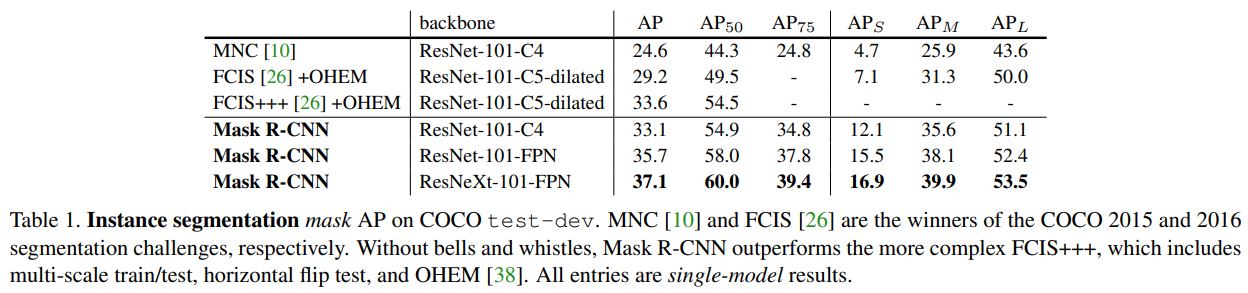
ResNet-101를 기본 base로 설정하고 output에 3가지 방식을 적용해서 비교했다.
ResNet-101-C4
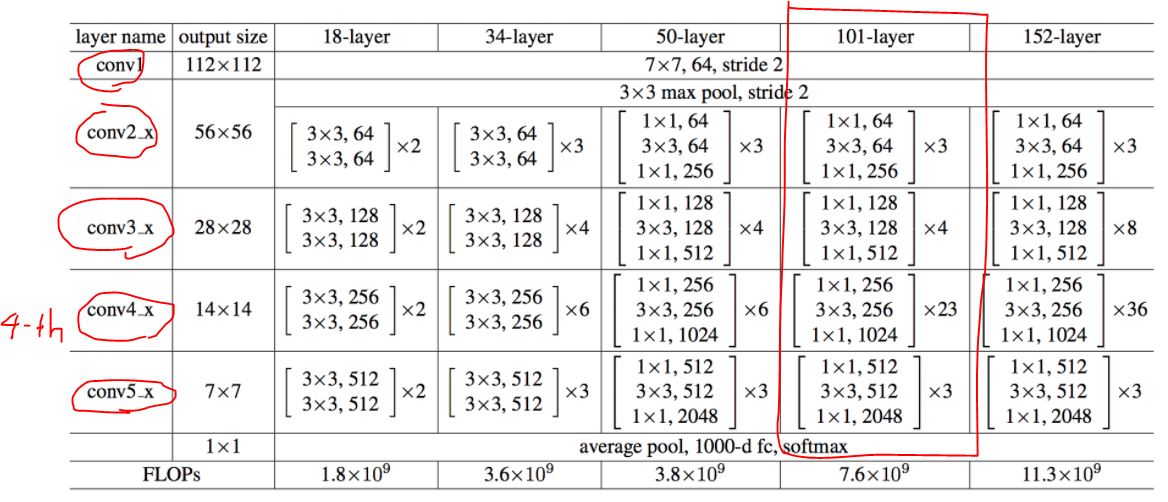
C-4은 논문에서 다음과 같이 설명햇다. Extracted features from the final convolutional layer of the 4-th stage, which we call C4. 즉, ResNet은 총 5개의 Layer블록으로 이루어져 잇는데, 그 중 4번째 Layer의 output을 C-4라고 칭하고, 해당 output을 backbone을 사용하겠다는 뜻이다.
ResNet-101-FPN
FPN은 Feature Pyramid Network를 말하고, Object Detection에서 사용되는 모델 중 하나이다. FPN은 backbone(여기서는 ResNet-101)이 CNN을 거쳐 downsampling을 하면서 feature를 추출하는 과정에서 사이사이에 생성되는 feature map을 따로 뽑아내 Prediction을 할 때 활용하는 방법이다.(FPN에 대한 자세한 방법은 아래에 설명하겠다.)
따라서 ResNet-101-FPN은 ResNet-101의 output과 FPN의 output을 결합한 형태이고, C-5가 포함되어 있는 구조이다.
ResNet vs ResNeXt
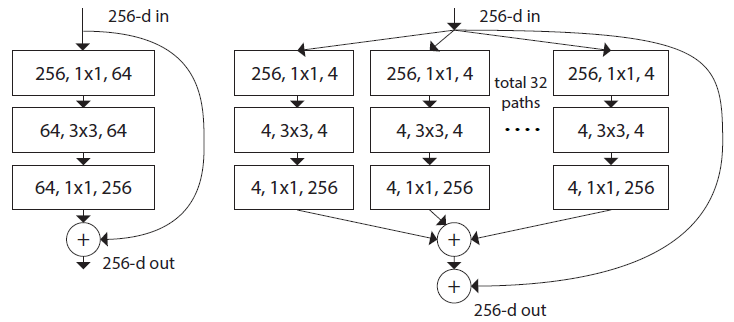
이름에서도 직감할 수 있듯이 ResNet과 ResNeXt은 비슷한 구조를 가지고 있다. 하지만 ResNeXt이 ResNet에 비해 발전된 형태이기 때문에 더욱 복잡한 구조를 하고 있다. ResNeXt은 한 개의 Layer마다 더 많은 feature를 추출하기 위해 설계되었다.
FPN(Feature Pyramid Network)
Feature Pyramid Networks for Object Detection를 통해 발표된 FPN모델은 Object Detection 테스크에서 사용하는 모델이다.
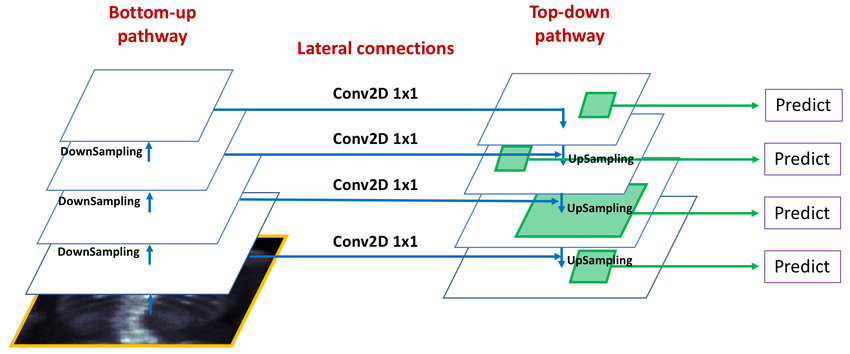
FPN은 Feature를 추출하는 Downsampling(Bottom-up)부분에서 CNN Layer 사이사이에서 생성되는 scale이 다른 feature map을 결합하면서 각 scale별로 물체를 예측하는 모델이다. 단지 DownSampling의 마지막 Feature map에서 물체를 예측하게 되면 여러 scale에 대한 다양한 물체를 얻기가 힘들기 때문에 이러한 방식이 도입되었다.
FPN의 Forward는 다음과 같다.
- Downsampling(bottom-up)과정을 통해 feature를 추출한다.
- 중간 Layer들의 feature map을 출력 후 저장
- Downsampling이 완료되면 가장 High level feature부터 중간에 추출한 feature map과 Top-down 방향으로 결합한다.
- 결합 시 1x1 Conv2d으로 channel수를 동일하게 만들고 element-wise하게 픽셀값을 더해서 Scale이 다른 feature map을 생성한다.
ResNet-101-FPN 또는 ResNeXt-101-FPN의 경우 FPN를 이용해 다양한 scale의 feature map을 생성한다. 생성된 feature map은 각 scale별로 Region Proposal Network(RPN)를 거쳐 bbox의 좌표와 objectness가 산출된다. 이후에 feature map과 projection시켜 RoI를 형성하고, RoIAlign Layer를 통해 모두 동일한 size로 변환한다.
RoIAlign
RoIAlign은 Fast-RCNN을 시작으로 Faster-RCNN까지 사용된 RoIPooling을 발전시킨 기법이다. RoIAlign이 나오게 된 이유는 Object Detection에 비해 Segmenation의 경우 더 정밀한 예측이 필요하기 때문이다. 약간의 오차에도 큰 차이가 날 수 있기 때문에 RoIPooling에서 불가피하게 발생하던 오차를 보완한 기법이다.
RoIPooling
먼저 기존에 사용되던 RoIPooling은 다음과 같다.
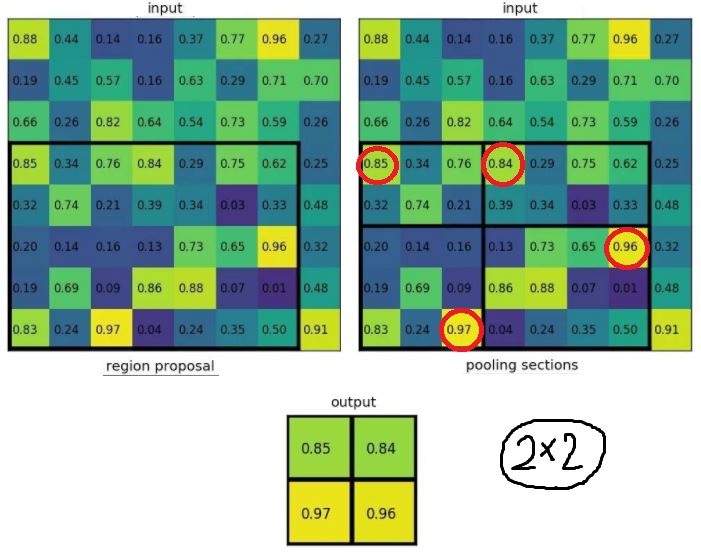
size가 7x5인 region Proposal이 있고, 원하는 output의 size는 2x2라고 하자. RoIpooling layer는 output이 2x2가 나올 수 있도록 가변적인 Filter를 적용해 출력한다. 위 예시의 경우 Region proposal을 4파트(2x2)로 나눈 후 각 파트별로 Maxpool을 적용했다. RoIpooling의 장점은 어떤 size의 이미지가 있어도 원하는 동일한 size로 변환할 수 있다는 것이다.
RoIPooling 문제점
하지만 문제는 bbox의 좌표를 산출할 때 발생한다. 위 예시와 같이 bbox의 좌표가 정확히 정수로 산출되었다면, 원하는 크기로 나눌 수 있고 그대로 maxpool을 적용할 수 있다. 하지만 bbox의 좌표는 보통 연속적인 값이기 때문에 만약 좌표와 길이가 소수점으로 산출되었다면 어떻게 계산될까? RoIPooling을 적용하기 위해 소수점을 버림한다. 따라서 버려진 소수점으로부터 데이터의 손실이 발생하고, bbox의 위치가 정확히 산출되지 않아 Segmentation을 위해 Mask를 예측할 때 정확도가 낮아지는 문제를 야기한다.
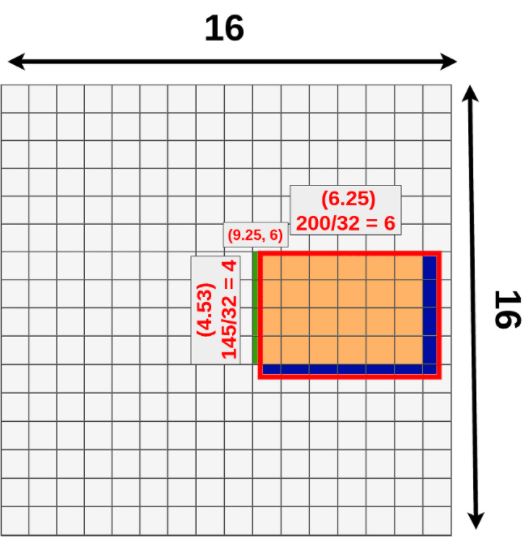
위 그림에서 초록색과 파란색 부분이 bbox의 좌표를 정수로 만들면서 발생하는 오차에 해당한다. 따라서 이러한 오차를 최소화하기 위해 고안해낸 방법이 RoIAlign이다.
RoIAlign
RoIAlign의 핵심은 소수점으로 발생한 오차를 최대한 보완하는 것이다. 오차를 최소화하기 위해 소수점이 산출되어도 ‘bbox의 좌표값’도 그대로 보존하는 동시에 ‘픽셀값’도 소수점인 상태에서 계산을 한다. 원리는 Bilinear Interpolation을 이용해 소수점에 의해 걸쳐져있는 주위 픽셀값들로부터 산출한다.
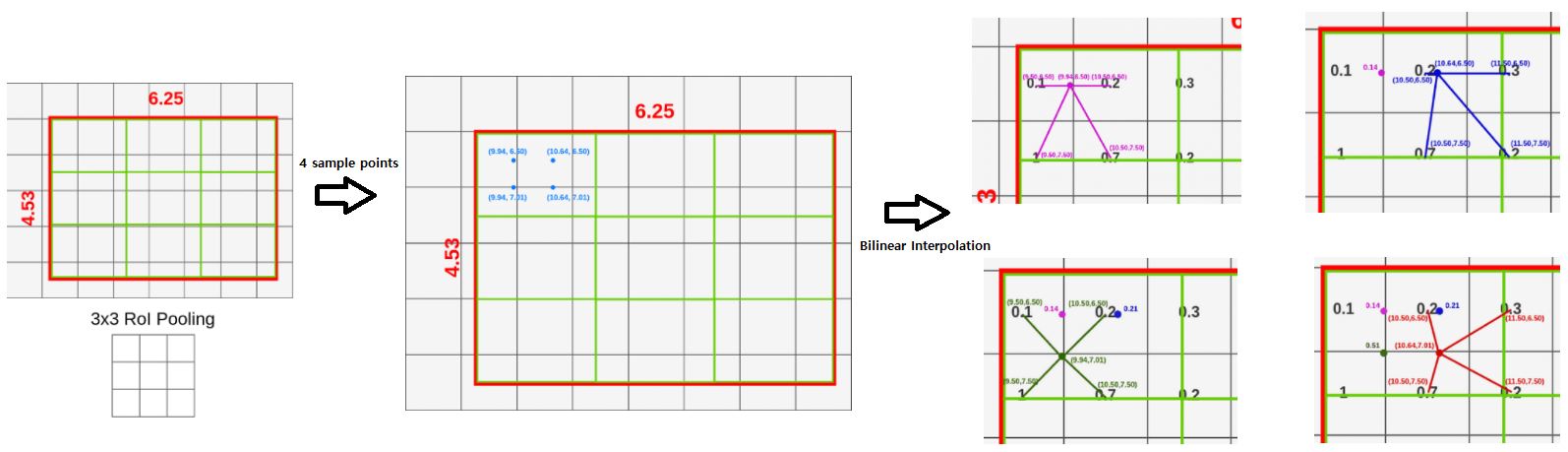
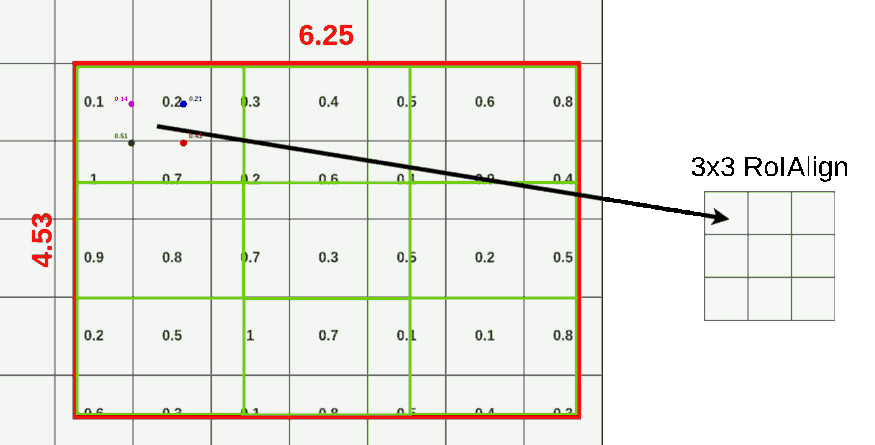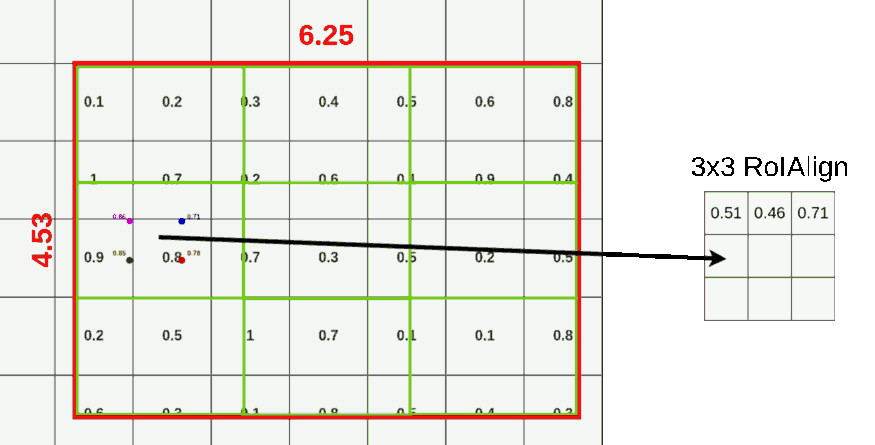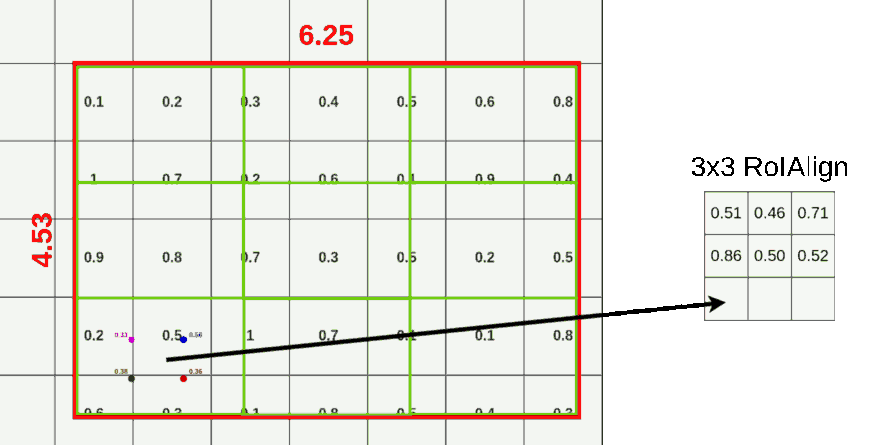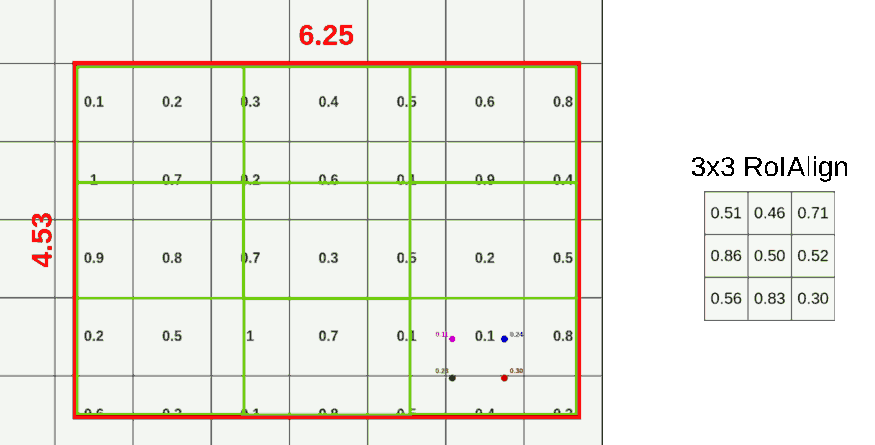
RoIAlign의 과정은 다음과 같다.(output의 size를 3x3으로 출력한다고 가정하자.)
- RoI의 가로,세로를 3등분으로 나눈다.(각 구역을 cell이라고 하자.)
- 1개의 cell안에 균등한 간격으로 4개의 sample points를 생성한다.(가로, 세로 균등하게)
- 각 points 주위 픽셀들로부터 bilinear interpolation을 적용해 point별로 값을 산출한다.
- 값이 산출된 4개의 point를 Maxpool 또는 Avepool을 통해 1개의 픽셀값으로 합친다.
- 나눠진 모든 cell에 대해 (2)~(4)과정을 반복한다.
아래는 RoIAlign 과정을 그림으로 표현했다.
Loss
Mask-RCNN에는 총 3가지의 결과물이 있는데, 물체의 class를 예측하는 classification, 위치를 보정하는 bbox regression, 그리고 mask를 생성하는 Segmentation가 있다. 따라서 Loss도 3가지 종류가 존재한다. Loss는 N개의 RoI에 대해 계산을 한다.(1개의 input 이미지에 100개의 RoI가 생성된다.)
Mask-RCNN의 특징 중 하나는 Loss가 2-stage로 분리되어있다. Faster-RCNN head부분인 $L_{cls}$ + $L_{box}$와 Mask-RCNN head부분인 $L_{mask}$으로 나눠져서 독립적으로 Loss가 산출된다.
$Loss_{cls}$ & $Loss_{box}$
먼저 classification을 위한 loss와 box의 좌표보정을 위한 loss이다. 이 부분은 Faster-RCNN과 동일하게 계산된다. N개의 RoI에 대해 적용이 된다. $Loss_{cls}$ 경우 softmax를 통해 loss가 산출되고, $Loss_{box}$의 경우 box regression을 통해 좌표값의 차이에 대한 loss가 산출된다.
$Loss_{mask}$
Segmentation을 위해 생성한 mask에 대한 loss값이다. Mask Branch에서 class의 개수만큼 Mask를 출력하는데, 실제로 loss에 사용되는 mask는 class에 대한 mask이다. 즉, mask branch의 output이 CxWxH이고, C가 class의 개수, 해당 RoI의 class가 c일 때 CxWxH 중 c번째 Mask만 뽑아낸 후 정답 mask와 비교하여 loss를 계산한다. class에 해당하는 1개의 mask만 뽑아내 계산이 가능한 이유는 mask가 binary 데이터이기 때문이다.
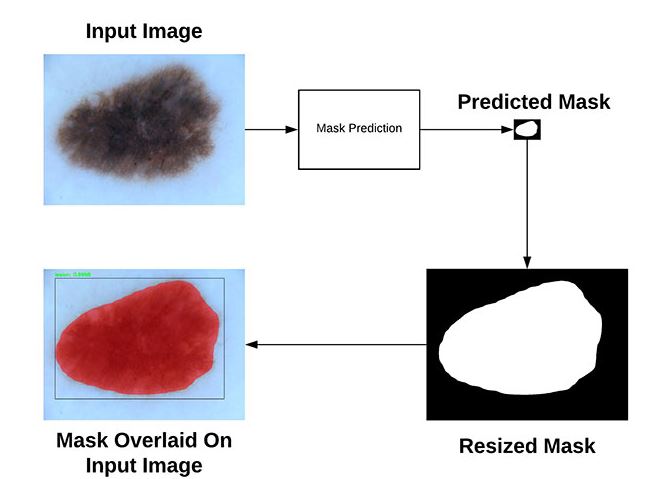
Human Pose Estimation
Mask-RCNN은 Segmenation뿐만 아니라 Key-points detection을 이용한 Humans Pose Estimation에도 활용할 수 있다.

Key-points를 예측하는 방법은 위에서 Segemtation을 진행한 절차와 동일하다. 하지만 Mask-RCNN Head에서 Mask를 예측하는 부분이 Object Mask에서 Key-points Mask로 대체된다. 즉, Object에 활용할 때는 class의 개수만큼 mask의 channel이 나오지만 Key-Points에 활용할 때는 key-Points의 개수만큼 Mask의 channel이 생성된다. 따라서 각 channel은 key-point에 대응되고, 각 key-point별로 대응되는 mask만 뽑아서 학습을 진행한다.(loss 계산 시)
Ablation Sutdy
Mask-RCNN 논문에서는 다양한 Ablation 실험을 진행했다. 최적의 Mask-RCNN모델을 찾기 위해 여러 노력을 한 것 같다.(위에서 다룬 내용 중에 중복된 것도 있을 수 있다.)
- 모델이 깊고 복잡할수록 상대적으로 좋은 성능을 보인다. 하지만 속도는 느리다.
- RoIPool, RoIWrap, RoIAlign 3가지를 비교했을 때 RoIAlign의 성능이 가장 좋았다.
- CityScopse Dataset을 이용해서 실험을 했을때도 Mask-RCNN의 성능이 가장 좋았다.
- Mask와 classification&bbox를 분리했을 때(Softmax가 아닌 Sigmoid) 성능이 더 좋았다.
- Mask를 생성하는 Layer를 설계할 때 MLP보다 FCN방식이 더 좋은 성능을 보였다.(공간정보 보존)
지금까지 Mask-RCNN에 대해 알아보았다. Instance Segmentation이기 때문에 기존 Segmentation모델들보다 더 정교하고 정밀한 계산이 필요해 여러가지 테크닉이 적용된 것 같다. 그리고 Object Detection테스크에 비해 Segmentation테스크가 더 많은 계산량을 요구하는 것 같다. Mask-RCNN은 지금까지도 다양한 모델의 Backbone으로 사용되고 있기 때문에 매우 좋은 모델로 평가받고 있다.