이전 포스터에서 나만의 dataset 만드는 방법에 대해 알아보았다. 흔히 아는 MNIST나 CIFAR10 데이터가 아닌 직접 수집한 데이터를 이용하기 위해서 Custom한 Dataset을 만들었다. custom한 dataset을 정의하는 방법에 중점적으로 알아보았다. 이번 포스터에서는 Pytorch에서 제공하고 있는 공개된 dataset을 사용하는 방법에 대해 알아볼 예정이다. 전체 코드는 여기에서 볼 수 있다.
torch: 1.7.1torhcvision: 0.8.2
유명한 Dataset
흔히 모델의 성능을 평가할 때 공개된 데이터셋을 자주 사용한다. Classification의 경우 ImageNet 데이터셋을 자주 사용하고, Detection의 경우 COCO 또는 PASCAL 데이터셋을 사용한다. 대부분의 논문에서 사용하기 때문에 매우 유명한 데이터셋이다. Pytorch에서도 이러한 데이터를 쉽게 이용할 수 있도록 클래스를 제공한다.

몇 개의 데이터셋을 제외하고는 대부분 download메소드도 같이 제공하기 때문에 코드 한 줄로 다운로드를 받을 수 있다. 보통 용량들이 크기 때문에 시간이 많이 걸린다. 편리하게 이용할 수 있다면야 시간은 문제가 될 것 같진 않다.
PASCAL-VOC Dataset

PASCAL-VOC 데이터셋은 Computer Vision 연구하는데 사용되는 대표적인 데이터이다. 크게 Object Detection과 Segmentation을 위한 데이터가 있다. 여러 해를 거쳐 다양한 대회가 주최되었고, 그때마다 성능이 좋은 모델들이 많이 탄생했다. 약 20개 클래스로 이루어져 있다.
바로 코드를 통해 PASCAL-VOC 데이터셋을 이용하는 방법에 대해 알아보자.
Pytorch 실습
많은 데이터가 있지만 대표적으로 PASCAL VOC 데이터셋을 이용해 실습을 진행하려고 한다. 그 이유는 class의 개수(20개)도 적당하고 개인적으로 Object Detection에 관심이 많기 때문이다. PASCAL VOC는 보통 Detetction과 Segmentation 분야에서 많이 사용되는 데이터셋이다. 그리고 이후에 PASCAL VOC 데이터셋을 이용해 가장 기본적인 Object Detection모델을 학습시키는 것도 진행할 예정이다.(Faster-RCNN 모델)
아래는 torchvision 라이브러이에서 PASCAL VOC 데이터셋을 불러오는 코드이다.
import torchvision.transforms as transforms
from torchvision.datasets import VOCDetection
data_path = '../../data'
dataset_default = VOCDetection(root=data_path, year='2012',
image_set='train', download=True,
transform=transforms.ToTensor())
dataset_default
# Dataset VOCDetection
# Number of datapoints: 5717
# Root location: ../../data
# StandardTransform
# Transform: ToTensor()
- PASCAL VOC 데이터셋은 년도별로 데이터가 다르다. 필자는 2012년을 이용하고자 한다.
image_set: train, trainval, val 총 3가지 종류가 있다. 보통 train과 trainval을 train으로, val을 test이미지로 사용한다고 한다.
transform 인자에 대해 애기해보면, PASCAL Dataset에 있는 이미지 데이터는 PIL 데이터이다. 즉, 이미지를 PIL.Image.open()로 불러왔을 때의 type이다. 만약 ToTensor() 설정하지 않으면 다음 차례로 사용할 메소드인 DataLoader에서 다음과 같은 오류가 발생한다.
TypeError: default_collate: batch must contain tensors, numpy arrays, numbers, dicts or lists; found <class 'PIL.Image.Image'>
- 이미지 행렬을 tensor로 묶을 때 type이 tensor 또는 Numpy여야하는데, 다른 type일 시 오류가 발생한다.
바로 다음 순서인 DataLoader를 사용해보자.
from torch.utils.data import DataLoader
dataset_loader = DataLoader(dataset_default)
iter(dataset_loader).next()
# [tensor([[[[1.0000, 1.0000, 1.0000, ..., 0.7922, 0.7961, 0.8000],
# [1.0000, 1.0000, 1.0000, ..., 0.7961, 0.7961, 0.7922],
# [1.0000, 1.0000, 1.0000, ..., 0.8078, 0.8039, 0.8039],
# ...,
# [0.8039, 0.7608, 0.8078, ..., 0.5373, 0.4706, 0.4667],
# [0.7529, 0.7569, 0.7569, ..., 0.4353, 0.4235, 0.4784],
# [0.6980, 0.7059, 0.7255, ..., 0.3216, 0.2863, 0.3137]],
# [[1.0000, 1.0000, 1.0000, ..., 0.8039, 0.8078, 0.8118],
# [1.0000, 1.0000, 1.0000, ..., 0.8078, 0.8078, 0.8039],
# [1.0000, 1.0000, 1.0000, ..., 0.8196, 0.8157, 0.8157],
# ...,
# [0.7490, 0.7059, 0.7529, ..., 0.5020, 0.4392, 0.4431],
# [0.6980, 0.7020, 0.7020, ..., 0.4157, 0.4039, 0.4667],
# [0.6431, 0.6510, 0.6706, ..., 0.3020, 0.2667, 0.3020]],
# [[1.0000, 1.0000, 1.0000, ..., 0.9725, 0.9765, 0.9804],
# [1.0000, 1.0000, 1.0000, ..., 0.9765, 0.9765, 0.9725],
# [1.0000, 1.0000, 1.0000, ..., 0.9882, 0.9843, 0.9843],
# ...,
# [0.6980, 0.6549, 0.7020, ..., 0.4667, 0.3961, 0.3961],
# [0.6471, 0.6510, 0.6510, ..., 0.3922, 0.3804, 0.4314],
# [0.5922, 0.6000, 0.6196, ..., 0.2863, 0.2510, 0.2745]]]]),
# {'annotation': {'folder': ['VOC2012'],
# 'filename': ['2008_000008.jpg'],
# 'source': {'database': ['The VOC2008 Database'],
# 'annotation': ['PASCAL VOC2008'],
# 'image': ['flickr']},
# 'size': {'width': ['500'], 'height': ['442'], 'depth': ['3']},
# 'segmented': ['0'],
# 'object': [{'name': ['horse'],
# 'pose': ['Left'],
# 'truncated': ['0'],
# 'occluded': ['1'],
# 'bndbox': {'xmin': ['53'],
# 'ymin': ['87'],
# 'xmax': ['471'],
# 'ymax': ['420']},
# 'difficult': ['0']},
# {'name': ['person'],
# 'pose': ['Unspecified'],
# 'truncated': ['1'],
# 'occluded': ['0'],
# 'bndbox': {'xmin': ['158'],
# 'ymin': ['44'],
# 'xmax': ['289'],
# 'ymax': ['167']},
# 'difficult': ['0']}]}}]
결과를 보면 이미지 데이터와 이미지 속 object에 대한 class, bbox의 좌표 등이 포함되어 있다. 한 이미지 속에 여러 object에 존재할 수 있기 bbox와 class도 여러 개가 출력된다. 아쉽게도 이러한 구조는 바로 학습에 사용할 수 없다. 따라서 학습에 편리하게 이용하기 위해 약간의 변형을 해줘야한다. 물론 저 상태에서 또 다른 메소드를 정의해 전처리해주는 방법도 있지만, 애초에 dataset을 만드는 단계에서 전처리를 해주면 코드가 좀 더 깔끔해진다. 따라서 VOCDetection 클래스를 상속받아 dataset 클래스를 customize해보겠다.
- class를 string 에서 int로 라벨링
- bbox의 좌표를 행렬로 변환
- target과 label을 tensor로 변환
VOCDetection 메소드 customize
VOCDetection 클래스를 상속받으면 기존 클래스에 있던 대부분의 함수들은 사용할 수 있다. 클래스 원본은 여기에서 확인할 수 있다. 필자는 데이터를 출력하는 부분인 __getiem__ 메소드만 수정하고 나머지 메소드는 그대로 사용할 예정이다. 또한 class에 대한 정보는 여기에서 확인할 수 있다.
아래 코드는 __getitem__ 메소드만 수정해서 정의한 dataset 클래스이다.
# PASCAL VOC classes
classes = ['__background__', 'aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus',
'car', 'cat', 'chair', 'cow', 'diningtable', 'dog', 'horse', 'motorbike',
'person', 'pottedplant', 'sheep', 'sofa', 'train', 'tvmonitor']
class myVOCDetection(VOCDetection):
def __getitem__(self, index):
# self.images : list of image path
img = Image.open(self.images[index]).convert('RGB')
target = self.parse_voc_xml(ET_parse(self.annotations[index]).getroot()) # xml 불러오기
# object별로 dictionary에서 bbox와 class 불러오기
targets, labels = [], []
for t in target['annotation']['object']:
bbox = [int(t['bndbox']['xmin']), # bbox 좌표값
int(t['bndbox']['ymin']), # 값이 str형으로 되어 있어서 int로 변환
int(t['bndbox']['xmax']),
int(t['bndbox']['ymax'])]
label = classes.index(t['name']) # classes 리스트에서 index값
targets.append(bbox)
labels.append(label)
# label의 경우 torch로 변환하는 것 외에는 transform해줄게 없음
# 따라서 label만 따로 적용
labels = torch.tensor(labels)
if self.transform:
img = self.transform(img)
targets = self.transform(np.array(targets)) # targets : list -> array
return img, targets, labels
def collate_fn(batch):
return tuple(zip(*batch))
정의된 클래스를 불러온 후에 dataloader를 적용해보자.
data_path = '../../data'
datasets = myVOCDetection(root=data_path, year='2012', image_set='train', transform=transforms.ToTensor())
dataloader = DataLoader(datasets, batch_size=1)
images, bboxes, labels = iter(dataloader).next()
images, bboxes, labels
# (tensor([[[[1.0000, 1.0000, 1.0000, ..., 0.7922, 0.7961, 0.8000],
# [1.0000, 1.0000, 1.0000, ..., 0.7961, 0.7961, 0.7922],
# [1.0000, 1.0000, 1.0000, ..., 0.8078, 0.8039, 0.8039],
# ...,
# [0.8039, 0.7608, 0.8078, ..., 0.5373, 0.4706, 0.4667],
# [0.7529, 0.7569, 0.7569, ..., 0.4353, 0.4235, 0.4784],
# [0.6980, 0.7059, 0.7255, ..., 0.3216, 0.2863, 0.3137]],
# [[1.0000, 1.0000, 1.0000, ..., 0.8039, 0.8078, 0.8118],
# [1.0000, 1.0000, 1.0000, ..., 0.8078, 0.8078, 0.8039],
# [1.0000, 1.0000, 1.0000, ..., 0.8196, 0.8157, 0.8157],
# ...,
# [0.7490, 0.7059, 0.7529, ..., 0.5020, 0.4392, 0.4431],
# [0.6980, 0.7020, 0.7020, ..., 0.4157, 0.4039, 0.4667],
# [0.6431, 0.6510, 0.6706, ..., 0.3020, 0.2667, 0.3020]],
# [[1.0000, 1.0000, 1.0000, ..., 0.9725, 0.9765, 0.9804],
# [1.0000, 1.0000, 1.0000, ..., 0.9765, 0.9765, 0.9725],
# [1.0000, 1.0000, 1.0000, ..., 0.9882, 0.9843, 0.9843],
# ...,
# [0.6980, 0.6549, 0.7020, ..., 0.4667, 0.3961, 0.3961],
# [0.6471, 0.6510, 0.6510, ..., 0.3922, 0.3804, 0.4314],
# [0.5922, 0.6000, 0.6196, ..., 0.2863, 0.2510, 0.2745]]]]),
# tensor([[[[ 53, 87, 471, 420],
# [158, 44, 289, 167]]]], dtype=torch.int32),
# tensor([[13, 15]]))
바로 학습을 할 수 있을 것 같은 형태로 변환되었다.
문제점
위 코드를 보면 batch_size의 값을 1로 설정한 것을 알 수 있다. 만약 batch_size를 2이상으로 하면 어떻게 될까? 바로 실험해보자.
dataloader = DataLoader(datasets, batch_size=2)
images, bboxes, labels = iter(dataloader).next()
# RuntimeError: stack expects each tensor to be equal size, but got [3, 442, 500] at entry 0 and [3, 327, 500] at entry 1
에러가 발생한다. 해석해보면 ‘두 이미지의 사이즈가 달라 tensor행렬로 변환할 수 없다’는 내용이다. numpy에서도 그렇고 torch에서도 행렬(또는 tensor)로 표현하기 위해서는 각 row값이 모두 같은 size를 가지고 있어야한다. 즉, 1 batch 당 2개의 이미지가 같이 묶여야하는데, 두 이미지의 사이즈가 다르기 때문에 오류가 발생한 것이다.
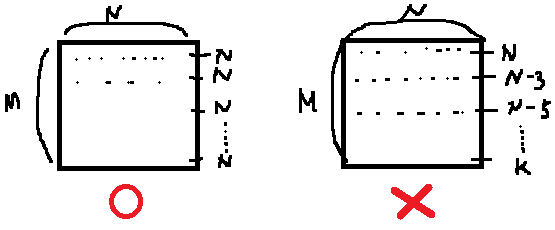
MNIST나 CIFAR10 등의 데이터셋은 모든 데이터의 사이즈가 동일하고, 모델도 고정된 사이즈의 데이터셋을 입력값으로 받기 때문에 애초에 문제가 발생하지 않았다. 하지만 object detection의 경우 다양한 사이즈의 데이터셋을 입력값으로 받기 때문에 이러한 문제가 발생한다. 이러한 문제는 이미지 batch를 찢어서 tuple로 만들어주면 해결된다. 행렬 대신 tuple을 사용해서 batch의 역할을 대신하는 것 뿐이다.
사용자가 원하는 형태의 데이터로 표현할 수 있도록 dataloader 메소드가 인자를 제공한다. collate_fn인자에 원하는 함수를 적용하면 바로 적용이 된다.
# batch를 찢은 후에 tuple로 변환
def collate_fn(batch):
return tuple(zip(*batch))
- *가 묶여있는 데이터셋을 찢는 역할을 한다.
- 이후에 tuple로 묶어서 출력하도록 조치
최종적으로 dataloader은 다음과 같다.
dataloader = DataLoader(datasets, batch_size=2, collate_fn=collate_fn)
images, bboxes, labels = iter(dataloader).next()
images
# (tensor([[[1.0000, 1.0000, 1.0000, ..., 0.7922, 0.7961, 0.8000],
# [1.0000, 1.0000, 1.0000, ..., 0.7961, 0.7961, 0.7922],
# [1.0000, 1.0000, 1.0000, ..., 0.8078, 0.8039, 0.8039],
# ...,
# [0.8039, 0.7608, 0.8078, ..., 0.5373, 0.4706, 0.4667],
# [0.7529, 0.7569, 0.7569, ..., 0.4353, 0.4235, 0.4784],
# [0.6980, 0.7059, 0.7255, ..., 0.3216, 0.2863, 0.3137]],
# [[1.0000, 1.0000, 1.0000, ..., 0.8039, 0.8078, 0.8118],
# [1.0000, 1.0000, 1.0000, ..., 0.8078, 0.8078, 0.8039],
# [1.0000, 1.0000, 1.0000, ..., 0.8196, 0.8157, 0.8157],
# ...,
# [0.7490, 0.7059, 0.7529, ..., 0.5020, 0.4392, 0.4431],
# [0.6980, 0.7020, 0.7020, ..., 0.4157, 0.4039, 0.4667],
# [0.6431, 0.6510, 0.6706, ..., 0.3020, 0.2667, 0.3020]],
# [[1.0000, 1.0000, 1.0000, ..., 0.9725, 0.9765, 0.9804],
# [1.0000, 1.0000, 1.0000, ..., 0.9765, 0.9765, 0.9725],
# [1.0000, 1.0000, 1.0000, ..., 0.9882, 0.9843, 0.9843],
# ...,
# [0.6980, 0.6549, 0.7020, ..., 0.4667, 0.3961, 0.3961],
# [0.6471, 0.6510, 0.6510, ..., 0.3922, 0.3804, 0.4314],
# [0.5922, 0.6000, 0.6196, ..., 0.2863, 0.2510, 0.2745]]]),
# tensor([[[0.3216, 0.3412, 0.3647, ..., 0.6275, 0.6275, 0.6196],
# [0.3490, 0.3569, 0.3569, ..., 0.6235, 0.6196, 0.6078],
# [0.3647, 0.3569, 0.3412, ..., 0.6196, 0.6078, 0.5961],
# ...,
# [0.1804, 0.1569, 0.1255, ..., 0.1686, 0.1804, 0.1922],
# [0.2078, 0.1882, 0.1961, ..., 0.1882, 0.2000, 0.2118],
# [0.2471, 0.2235, 0.2549, ..., 0.2314, 0.2471, 0.2627]],
# [[0.4235, 0.4431, 0.4706, ..., 0.4118, 0.4118, 0.4039],
# [0.4510, 0.4588, 0.4627, ..., 0.4078, 0.4039, 0.3922],
# [0.4667, 0.4588, 0.4471, ..., 0.4039, 0.3922, 0.3804],
# ...,
# [0.1569, 0.1294, 0.0863, ..., 0.0471, 0.0588, 0.0706],
# [0.1843, 0.1647, 0.1686, ..., 0.0588, 0.0706, 0.0824],
# [0.2235, 0.2000, 0.2157, ..., 0.1020, 0.1176, 0.1333]],
# [[0.5137, 0.5333, 0.5529, ..., 0.2000, 0.2000, 0.1922],
# [0.5412, 0.5490, 0.5451, ..., 0.1961, 0.1922, 0.1804],
# [0.5569, 0.5490, 0.5294, ..., 0.1922, 0.1804, 0.1686],
# ...,
# [0.1961, 0.1608, 0.1216, ..., 0.0275, 0.0392, 0.0510],
# [0.2314, 0.2039, 0.2000, ..., 0.0392, 0.0510, 0.0627],
# [0.2784, 0.2471, 0.2588, ..., 0.0824, 0.0980, 0.1137]]]))
- bboxes와 labels의 경우 동일한 형태를 가진다.
PASCAL VOC datsets에 대한 준비는 끝났다. 이제 각 모델에 맞게 train하는 과정에서 dataset을 약간 수정해 사용하면 된다. Faster-RCNN의 경우 이미지와 bboxes, labels를 각각 list로 받기 때문에 위와 같은 형태를 이용하면 매우 쉽게 코드를 작성할 수 있다. 위에 정의한 PASCAL VOC dataset을 자유롭게 이용하기 위해 python파일로 만들어서 사용할 예정이다. 이후에는 Faster-RCNN을 이용해 학습하는 내용도 다뤄볼 예정이다. 전체 코드는 여기에서 볼 수 있다.