인공신경망에 대한 전반적인 내용은 앞 글에서 충분히 다루었다고 생각한다. 따라서 이번 글에서는 실제 데이터를 이용해 분류(Classification)를 하는 프로젝트를 진행해보기로 하자. (배움을 위해 모델은 직접 정의한 후 진행하기로 하자.)
진행 순서는 다음과 같다.
- 데이터 정의 및 불러오기(CIFAR10)
- 모델 정의
- GPU 사용여부 확인
- 손실 함수(Loss Function) 및 최적화 함수(Optimizer) 정의
- 하이퍼 파라미터(Hyper Parameter) 정의
- 학습 진행
- 모델 평가
데이터 정의 및 불러오기(CIFAR-10)
데이터
이번 프로젝트에서 사용할 데이터는 CIFAR-10 Datasets이다. 32x32 크기의 이미지가 약 6만개 정도 포함되어 있는 데이터셋이며, 각 이미지는 10개의 클래스 중 하나로 라벨링이 되어 있다. 머신러닝을 연구할 때 가장 많이 사용되는 데이터셋 중 하나이다.

6만개의 이미지 중 5만개는 학습(Train)에 이용하고 나머지 1만개는 평가(Test)에 사용하도록 하겠다. 그렇다면 이 데이터를 어떻게 불러올까?
데이터 정의
Pytorch에서는 이러한 데이터셋을 쉽게 불러올 수 있도록 하는 라이브러리인 torchvision을 제공한다. 이 라이브러리는 여러 딥러닝 분야 중 Vision분야를 다룰 때 매우 유용하게 사용되고 있다. 데이터를 불러오는 코드는 다음과 같다.
import torchvision
import torchvision.transforms as transforms
transform = transforms.Compose(
[
transforms.ToTensor(), # Tensor로 변환하기
transforms.Normalize([0], [1]) # 정규화(평균(m) = 0, 표준편차(std) = 1)
])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transforms)
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=False, transform=transforms)
torchvision.datasets에 있는 데이터 중 CIFAR10을 정의했다.
root: 데이터의 위치(./data = 현재 디렉토리 안에 data폴더)train: CIFAR10 데이터셋 내부적으로 train용과 test용으로 나눠져있다. 따라서 True로 설정 시 train용, False로 설정 시 test용 데이터셋을 정의한다.downlaod:root에 데이터가 없으면 자동으로 다운로드를 한다.transform: 데이터를 전처리하거나 부풀리기 등의 기능을 추가
데이터를 확인하면 다음과 같다.(각각 5만개, 1만개)
>>> print(trainset)
# Dataset CIFAR10
# Number of datapoints: 50000
# Root location: ./data
# Split: Train
# StandardTransform
# Transform: Compose(
# ToTensor()
# Normalize(mean=[0], std=[1])
# )
>>> print(testset)
# Dataset CIFAR10
# Number of datapoints: 10000
# Root location: ./data
# Split: Test
# StandardTransform
# Transform: Compose(
# ToTensor()
# Normalize(mean=[0], std=[1])
# )
데이터 불러오기(DataLoader)
데이터 정의를 완료했으면, 이제 데이터를 학습에 용이하게 불러와야한다. 이 방법 또한 Pytorch에서 편리한 모듈을 제공하고 있다. DataLoader를 사용하면 매우 편리하게 데이터를 불러올 수 있다.
import torch
trainloader = torch.utils.data.DataLoader(dataset=trainset, batch_size=64, shuffle=True)
testloader = torch.utils.data.DataLoader(dataset=testset, batch_size=16, suffle=False)
torch.utils.data에 있는 DataLoader를 호출했다.
dataset: 앞에서torchvision.datasets을 통해 정의한 데이터셋이다.batch_size: 한 번 불러올 때 몇 개의 이미지를 불러올건지 정하는 옵션shuffle: 불러오기 전에 데이터를 섞을 수 있다.(test에서 안 섞는 이유는 평가는 항상 동일한 상태에서 비교를 해야하기 때문이다.)
데이터의 형태는 다음과 같다.
>>> type(iter(trainloader).next())
# list
>>> len(iter(trainloader).next())
# 2
>>> iter(trainloader).next()[0].size()
# torch.Size([64, 3, 32, 32])
>>> iter(trainloader).next()[1].size()
>>> print(iter(trainloader).next()[0])
# tensor([[[[0.8863, 0.8627, 0.8745, ..., 0.3569, 0.5882, 0.6039],
# [0.5765, 0.5451, 0.5647, ..., 0.3137, 0.3765, 0.4039],
# [0.4235, 0.4039, 0.3765, ..., 0.3098, 0.3569, 0.3490],
# ...,
# [0.6118, 0.5961, 0.5804, ..., 0.3882, 0.4392, 0.5843],
# [0.5961, 0.5882, 0.5882, ..., 0.5451, 0.5451, 0.5804],
# [0.5961, 0.5843, 0.5922, ..., 0.5961, 0.5725, 0.5765]],
# [[0.9098, 0.8824, 0.8824, ..., 0.3216, 0.5804, 0.6275],
# [0.5922, 0.5373, 0.5373, ..., 0.2706, 0.3451, 0.3882],
# [0.4078, 0.3686, 0.3216, ..., 0.2627, 0.3020, 0.2902],
# ...,
# [0.5647, 0.5490, 0.5333, ..., 0.3412, 0.3804, 0.5020],
# [0.5490, 0.5412, 0.5412, ..., 0.4667, 0.4627, 0.4902],
# [0.5490, 0.5373, 0.5451, ..., 0.4902, 0.4667, 0.4784]]],
# ...,
# [[[0.0549, 0.1529, 0.1216, ..., 0.3059, 0.2863, 0.2588],
# [0.1255, 0.2235, 0.2000, ..., 0.3765, 0.3961, 0.3569],
# [0.1529, 0.2118, 0.2039, ..., 0.3922, 0.3922, 0.3961],
# ...,
# [0.3529, 0.8275, 0.8118, ..., 0.1804, 0.1647, 0.1882],
# [0.3647, 0.8431, 0.8745, ..., 0.2275, 0.2549, 0.2353],
# [0.3294, 0.7686, 0.7961, ..., 0.2588, 0.3176, 0.3020]],
# [[0.1373, 0.2510, 0.2824, ..., 0.4706, 0.4471, 0.3686],
# [0.0980, 0.1961, 0.2353, ..., 0.4667, 0.4784, 0.3882],
# [0.0902, 0.1451, 0.2039, ..., 0.4431, 0.4275, 0.3843],
# ...,
# [0.3686, 0.8824, 0.9216, ..., 0.1647, 0.1882, 0.2235],
# [0.3804, 0.8980, 0.9882, ..., 0.1765, 0.2471, 0.2471],
# [0.3922, 0.8667, 0.9490, ..., 0.2588, 0.3647, 0.3725]]]])
>> print(iter(trainloader).next()[1])
# tensor([7, 5, 5, 8, 2, 2, 0, 8, 7, 1, 2, 5, 8, 8, 4, 5, 9, 3, 4, 1, 5, 8, 3, 6,
# 3, 3, 8, 1, 1, 2, 7, 6, 6, 5, 1, 0, 6, 3, 8, 0, 1, 8, 2, 4, 3, 9, 4, 2,
# 6, 8, 6, 2, 9, 6, 0, 6, 0, 2, 0, 9, 4, 6, 0, 8, 2, 8, 1, 4, 8, 1, 6, 4,
# 1, 1, 0, 5, 3, 9, 8, 6, 0, 2, 3, 6, 7, 9, 3, 2, 3, 6, 3, 4, 9, 8, 3, 7,
# 1, 8, 5, 8, 0, 7, 7, 0, 8, 1, 4, 4, 0, 6, 9, 4, 6, 3, 0, 4, 8, 9, 8, 8,
# 9, 5, 3, 3, 1, 5, 8, 6])
iter()함수를 통해 trianloader의 내장함수인 __iter__()을 실행시켜 iterator로 만들어주고, next()함수를 이용해 __next__()을 실행시켜 첫 데이터를 가져온 것이다. trainloader는 2개로 나눠지는데, 첫 번째는 이미지의 array이고 두 번째는 각 이미지에 대한 class label이다. size을 보면 [64, 3, 32, 32]인 것을 알 수 있는데, 각 자리는 다음과 같다.
실제로 이미지가 어떻게 생겼는지 출력하면 다음과 같다.
import matplotlib.pyplot as plt
def show(img):
print(img.size())
# make_grid 함수는 3채널로 만든다(모두 같은 format으로)
grid = torchvision.utils.make_grid(img, padding = 0)
tranimg = grid.permute(1,2,0)
plt.imshow(tranimg)
images, labels = iter(trainloader).next()
show(images)
make_grid(): 이미지를 사용자가 보기 쉽게 grid형태로 출력해준다.(입력값은 3채널이어야 함)padding: grid형태로 만들 때 이미지 사이의 공간을 만든다.(그 공간을 0값으로 채운다)permute(): Tensor의 shape을 재설정한다.((1,2,0) = 기존에 1행을 0행, 2행을 1행, 0행을 2행으로)
위 코드를 실행하면 아래 사진과 같이 출력이 된다.
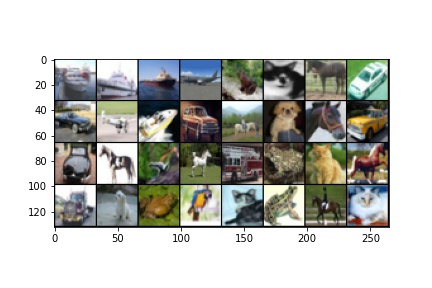
모델 정의
데이터를 준비했으면 다음은 모델을 정의해야 한다. 이미 검증된 많은 모델들이 있지만 공부를 위해 임의로 정의를 하겠습니다.
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=10, kernel_size=(5, 5)) #
self.conv2 = nn.Conv2d(in_channels=10, out_channels=20, kernel_size=(5, 5))
self.conv3 = nn.Conv2d(20, 20, 5)
self.conv4 = nn.Conv2d(20, 10, 5)
self.pool = nn.MaxPool2d(2,2)
self.fc1 = nn.Linear(10 * 8 * 8, 800)
self.fc2 = nn.Linear(800, 400)
self.fc3 = nn.Linear(400, 100)
self.fc4 = nn.Linear(100, 10)
def forward(self, x): # 32 32
x = F.relu(self.conv1(x)) # 28 28
x = F.relu(self.conv2(x)) # 24 24
x = F.relu(self.conv3(x)) # 20 20
x = self.pool(F.relu(self.conv4(x))) # 8 8
x = x.view(-1, 10 * 8 * 8)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = F.relu(self.fc3(x))
x = self.fc4(x)
return x
nn.Conv2d(in_channels, out_channels, kernel_size): CNN Layer 함수이다. 처음 3개의 channel(R,G,B)로 시작해서 원하는 채널 개수만큼 연산을 한다.nn.MaxPool2d(kernel_size): kernel_size 내에서 최대값을 출력하는 layer이다.nn.Linear(in_size, out_size): Fully-connected layer이다.F.relu: ReLU 활성화 함수이다.view(): Tensor의 size을 바꿔주는 함수(flatten)
정의한 모델의 모양은 다음과 같다.
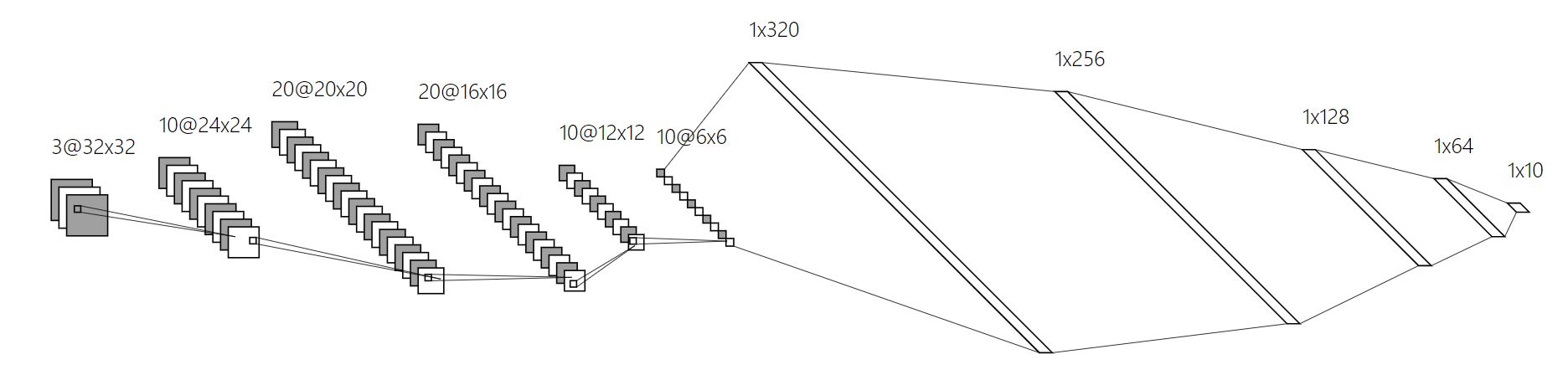
모델 확인
정의한 모델이 잘 작동되는지 테스트용으로 실행을 해보자.
model = Net()
model.eval()
model.to(device)
with torch.no_grad():
images, labels = next(iter(trainloader))
images, labels = images.to(device), labels.to(device)
example = model(images)
print(example.size())
print('Test : ', example)
eval(): 테스트용으로 설정하여 dropout이 비활성화되고 배치정규화(BN)가 학습할 때 지정했던 파라미터를 이용한다.torch.no_grad(): Autograd()모드를 비활성화하여 메모리 사용을 줄이고 연산속도를 증가시킨다.
단지 확인용으로 실행하는 코드이기에 eval()과 torch.no_grad()를 설정했다.
GPU 사용 여부 확인
GPU를 인공신경망 학습에 사용하게 되면서 학습속도가 매우 빨라졌다. Pytorch에서도 GPU를 사용할 수 있도록 하는 모듈을 제공하는데, cuda()를 이용하면 쉽게 GPU연산으로 변환할 수 있다.
if torch.cuda.is_available():
device = torch.device('cuda')
else:
device = torch.device('cpu')
>>>print(device)
# cuda
# 사용하는 방법
image.to(device), model.to(device)
현재 필자의 컴퓨터에는 GPU가 있기 때문에 device 가 cuda로 설정되었다. 나중에 연산에 참여하는 변수나 모델들을 .to()를 통해 GPU에 올릴 수 있다.
손실함수(Loss Function) 및 최적함 함수(Optimizer) 정의
분류문제에서 주로 사용하는 손실함수인 Cross Entropy Loss와 가장 보편적으로 많이 사용되는 최적화 함수인 Stochastic Gradient Descent를 이용하자.
loss_func = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr = 0.01)
>>> print(loss_func, optimizer)
# CrossEntropyLoss() SGD (
# Parameter Group 0
# dampening: 0
# initial_lr: 0.05
# lr: 0.05
# momentum: 0
# nesterov: False
# weight_decay: 0
# )
lr: 학습률은 기본적으로 0.01로 설정하자.
하이퍼 파라미터(Hypter Parameter) 설정
이 부분에서는 학습에 필요한 여러 파라미터들을 정의한다. 사람이 직접 설정해줘야 하기 때문에 여러 실험을 통해 찾아낼 필요가 있다. 하지만 이 포스터는 연습을 위한 것이기 때문에 임의의 숫자로 설정하겠다.
TRAIN_BATCH_SIZE = 16
TEST_BATCH_SIZE = 8
EPOCH = 10
Learning Rate도 하이퍼 파라미터에 포함되지만, 위에 최적화 함수를 정의하는 과정에서 이미 대입을 했기 때문에 생갹하기로 하겠다.
학습(Training)
위에서 정의했던 데이터, 모델, 손실 및 최적화 함수, 하이퍼 파라미터 등을 결합하여 학습을 진행하겠다.
import time
# Train
model.train()
for e in range(1, EPOCH+1):
start_time = time.time()
running_loss = 0
for i, data in enumerate(trainloader):
images, labels = data
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = loss_func(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss
now = time.time()
print('\r[%d/%d]-----[%d/%d] LOSS : %.3f------ Time : %d '
%(e, EPOCH, i+1, 60000/batch_size, running_loss, now - start_time), end = '')
print('\n')
# [1/10]-----[3125/3125] LOSS : 4602.747------ Time : 12
# [2/10]-----[3125/3125] LOSS : 4342.556------ Time : 12
# [3/10]-----[3125/3125] LOSS : 4199.608------ Time : 12
# [4/10]-----[3125/3125] LOSS : 4085.875------ Time : 12
# [5/10]-----[3125/3125] LOSS : 3990.505------ Time : 12
# [6/10]-----[3125/3125] LOSS : 3912.424------ Time : 12
# [7/10]-----[3125/3125] LOSS : 3834.343------ Time : 12
# [8/10]-----[3125/3125] LOSS : 3763.016------ Time : 12
# [9/10]-----[3125/3125] LOSS : 3684.760------ Time : 12
# [10/10]-----[3125/3125] LOSS : 3619.109------ Time : 12
train(): 모델을 학습 모드로 변경한다.(Dropout, BN 등 활성화)zero_grad():Autograd()로 계산 된 미분값 초기화backward(): 오차역전파 실시step(): 개매변수(가중치) 갱신
10 Epoch만 진행해서 아직 Loss가 많이 감소하지 않았지만, 계속 진행하면 더 떨어질 것으로 예상된다.
모델 평가(Testing)
trainset을 이용해서 학습을 완료했다면, testset을 이용해 모델의 성능을 평가해야한다. 평가방법은 여러가지가 있지만, 이번에는 아주 간단하게 ‘정확도’로 평가해보려고 한다. 전체 testset 중에 모델이 알맞게 예측한 이미지의 수를 측정하면 된다.
correct = 0
test_loss = 0
model.eval()
with torch.no_grad():
for data in testloader:
val_images, val_labels = data
val_images, val_labels = val_images.to(device), val_labels.to(device)
val_outputs = model(val_images)
pred = val_outputs.argmax(dim=1, keepdim=True)
correct += pred.eq(val_labels.view_as(pred)).sum().item()
>> print('Accuracy of the network on the 10000 test images : %.3f %%'
%(100 * correct / len(testloader.dataset)))
# Accuracy of the network on the 10000 test images : 46.370 %
no_grad(): Autograd()기능을 비활성하여 연산속도를 증가시키고 메모리 사용을 감소argmax(): 10개의 출력값 중 제일 높은 값(=해당 클래스일 확률)의 index를 출력한다.eq(tensor): tensor의 요소들과 일치하면 해당 index의 값을 1로 반환
위 결과에서는 고작 46%가 나왔지만, epoch을 더 늘리면 정확도가 더 올라갈 것으로 예상이 된다.
시작부터 Loss가 감소하지 않을 때 해결방안
# [1/10]-----[6250/7500] LOSS : 14400.677------ Time : 20
# [2/10]-----[6250/7500] LOSS : 14400.625------ Time : 20
# [3/10]-----[6250/7500] LOSS : 14401.487------ Time : 21
# [4/10]-----[6250/7500] LOSS : 14399.734------ Time : 20
# [5/10]-----[6250/7500] LOSS : 14400.587------ Time : 20
# [6/10]-----[6250/7500] LOSS : 14399.898------ Time : 20
# [7/10]-----[6250/7500] LOSS : 14400.886------ Time : 20
# [8/10]-----[6250/7500] LOSS : 14401.681------ Time : 20
# [9/10]-----[6250/7500] LOSS : 14400.815------ Time : 20
# [10/10]-----[6250/7500] LOSS : 14401.087------ Time : 20
가끔 학습을 진행할 때 Epoch이 진행이 되도 Loss가 감소하지 않는 상황이 발생한다. 물론 경사하강법의 특징에 의해 lr에 값에 따라 발산이 되어 진자운동처럼 손실함수값이 진동할 수 있지만, 대부분은 코드를 실행할 때 잘못된 순서로 인해 문제가 발생한다. 따라서 몇 개의 요소를 바꿔보면 해결이 되는 경우가 많다. 물론 이 방법은 어디까지나 학습이 아예 안 되는 것처럼 느껴질 때 해결방안이다.
(Loss가 잘 감소하고 있다가 어느 순간에 멈췄을 때는 lr값을 바꾸거나 모델 구조를 바꾸는 등 더 기술?적인 방법으로 해결해야 한다.)
1번부터 시도해보고 변화가 없다면 다음 번호로 넘어가자.
- 학습하는 코드에 .loss()와 .step()이 포함되어 있는지 확인(loss > step 순서 확인)
- 모델을 정의하고 불러온 후에 optimizer를 불러왔는지 확인
(
model = MyModel()을 실시한 후에SGD()를 정의했는지 확인) - optimizer에서 model.parameters()를 호출했는지 확인
- transform해서 Normalize 값을 0~1사이로 했는지 확인(굳이 0과 1사이일 필요는 없지만
lr도 잘 따져줘야함) lr값을 0.1 ~ 0.001 사이의 값으로 변경한 후에 시도
지금까지 CIFAR10 데이터셋을 이용해서 학습을 하는 과정에 대해 알아보았다. 위에서 다룬 내용은 학습을 처음 시도하는 사람들이 할 수 있는 가장 간단한 예시이다. 코드를 풀버젼으로 원하면 여기를 참고하면 된다. 사용하는 데이터에 따라서 모델도 바꿔줘야하고, 시간에 따라 lr값도 유동적으로 변경하는 scheduler 등의 테크닉도 이용해야한다. 앞으로 여러 테크닉들에게 대해 다룰 예정이다.