이번 포스터에서는 Multiple Object Tracking 분야에서 사용되는 모델 중 하나인 SORT에 대해 알아보자. SORT는 2017년 Simple Online and Realtime Tracking이라는 논문을 통해 발표되었다. 과거 Tracking 모델들은 정확도와 속도가 Trade-off관계를 가지고 있어서 속도가 빠르면 정확도가 낮고, 반대로 정확도가 높으면 속도가 느린 특징을 가지고 있었다. 하지만 SORT는 이러한 Trade-off를 깨고 속도와 정확도 모두 높은 성능을 보였다.
Abstract
이 논문에서는 online과 realtime에서 효과적인 association기법과 유용한 벙법론을 소개한다. Tracking을 하는데 있어서 Detector가 큰 요소로 작용하기 때문에 단순히 Detector를 바꾸기만 해도 성능이 약 18.9%가 증가하는 것을 보였고, 기본적인 테크닉인 Kalman Filter와 Hungarian Algorithm만으로도 정확도를 향상시켰다. 또한 다른 tracker들에 비해 매우 간단하다.
Introduction
SORT는 매우 간결한 MOT(Multiple object tracking) 모델 중 하나로 매 frame마다 detection이 이루어지고 tracking하여 bounding box를 생성하는 ‘tracking-by-detection’ framework이다. 과거frame과 현재frame을 사용하여 tracking을 하는 online 방식이며 실시간으로 tracking이 필요한 자율주행과 같은 분야에서 매우 효율적이다.
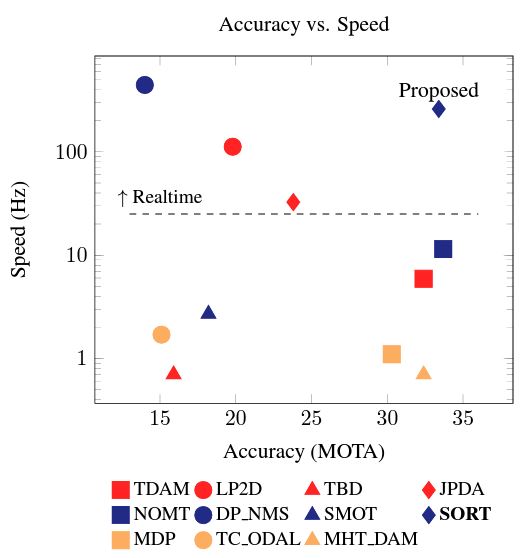
MOT는 data를 association하는 문제로 볼 수 있는데, 매 frame마다 발생하는 detection을 효율적으로 asscociation 하는 것이 궁극적인 목표이다. 이 논문에서는 그 당시 최신 MOT benchmark에서 사용된 여러 method에서 영감을 받았다고 한다.
- Multiple Hypothesis Tracking(MHT)과 Joint Probabilistic Data Association(JPDA) 같이 MOT benchmark 상위권에 존재하던 여러 좋은 data association techniques의 부활이 있었다.
- 유일하게 Aggregate Channel Filter(ACF) detector를 사용하지 않은 tracker가 benchmark 상위권을 차지했는데, 이것은 MOT의 성능이 Detector의 성능에 의해 좌지우지된다는 것을 의미한다.
- 이 밖에도 정확도(accuracy)와 속도(speed) 사이에는 trade-off가 존재한다.
이 논문에서는 Occam’s Razor(오캄의 면도날)을 따르기 위해 다음 같은 특징을 지녔다.
- Tracking을 하는데 있어서 Detection로부터 추출되는 feature들은 대부분 사용하지 않았고 motion-estimation과 data association을 위해 마지막 결과인 bounding box의 좌표값과 크기에 대한 정보만 사용했다.
- MOT의 대표적인 문제점인 short-term과 long-term occlusion도 신경쓰지 않았다. 실제로 occlusion은 잘 발생하지 않고 해당 문제를 해결하기 위해서는 복잡한 framework가 되어야하기 때문이다.
- Re-Identification에 대해서도 고민을 했지만 realtime application에는 큰 overhead를 주기 때문에 사용하지 않았다.
이러한 특징들은 다양한 error를 해결하기 위해 많은 전략들을 통합해놓은 다른 tracker들과 비교가 되지만, SORT는 frame과 frame을 association하는 것에 집중을 했다. detection error들에 대해 robust해지기 보다는 가장 최신 detector를 사용함으로써 직접적으로 detection error를 해결하는 전략을 사용했고 CNN기반의 ACF 보행자 detector와의 비교를 통해 그 성능을 증명했다. 더 나아가 매우 효과적이지만 전통적인 방법인 Kalman Filter와 Hungarian method를 사용해 motion estimation과 data association를 수행했다.
이 논문의 핵심은 다음과 같다.
- 강력한 기능을 하는 CNN기반의 detection을 사용했다.
- 매우 유용한 테크닉인 Kalman Filter와 Hungarian algorithm을 사용했고, 최신 MOT benchmark를 통해 성능을 평가했다.
- 코드를 공개해서 다양한 사람들이 baseline로 사용할 수 있도록 제공한다.
Literature review
과거에는 Multiple Hypothesis Tracking(MHT)이나 theJoint Probabilistic Data Association(JPDA) filters를 이용해 MOT문제를 해결했지만, Video가 dynamic한 환경이거나 tracking해야하는 object가 많아지면 조합 복잡도(combinatorial complexity)가 기하급수적으로 증가하여 realtime에는 사용하지 못했다.
- Rezatofighi et al는 integer programs를 해결하는데 사용하는 환경과 효율적인 근사치를 이용해 JPDA의 조합복잡도를 해결하려고 시도했다.
- Kim et al는 성능을 높이기 위해 각 target에 대해 appearance model를 적용해 MHT graph를 다듬는 방식을 사용했다. 하지만 여전히 online에는 적합하지 않았다.
- 많은 online tracking method들은 각각의 object 또는 model 전체에 대한 appearance를 만들기 위해 노력했다. 뿐만 아니라 motion(행동, 특정 물체가 하고자 하는 것)은 detection과 tracklets를 asscoication하기 위해 사용되었다.
- 만약 detection과 tracklets가 1대1 대응되는 경우만 생각한다면, 이분 매칭 그래프(bipartite graph matching)의 솔루션 중 하나인 Hungarian Algorithm가 사용되었다.
- Geiger et al는 Hungarian Algorithm을 two stage process로 사용했다. 첫 번째로, geometry와 appearance 정보를 결합해 만든 유사성 매트릭스로 형성된 인접 frame들에 거쳐 tracklets들은 detections와 associating하여 형성했다. 그리고 tracklets들은 occlusion에 의해 끊어진 trajecotry를 연결하기 위해 association되었다. 물론 이때도 geometry와 appearance의 정보가 이용되었다. 하지만 논문에서는 association을 더 간단하게 만들어 one stage방식을 사용했다.
Methodology
SORT는 다양한 요소로 구성되어 있다.
- Detection : 가장 중요한 detection
- Estimation : object의 상태를 미래frame으로 propagating하는 것
- Data Association : 현재frame의 detection과 기존에 존재하던 object(==target)와 assocation하는 것
- Creation and Deletion of Track Identities : Tracking하고 있는 object를 관리하는 것
하나하나 자세히 알아보기로 하자.
1. Detection
이 논문에서는 가장 최신의 CNN기반 Detector인 Faster RCNN(FrRCNN)모델을 사용했다. FrRCNN은 두 단계로 이루어져있는데, 첫 단계에서는 feature와 Region Proposal를 추출하고 두 번째 단계에서 분류를 하고 bounding box를 생성한다. 두 단계에서 사용되는 weight값이 공유가 되어 효율적이고 성능을 높이는 방향으로 모델의 구조를 자유롭게 변경할 수 있다는 장점이 있다. 논문에서는 Zeiler and Fergus의 FrRCNN(ZF)과 Simonyan and Zisserman의 FrRCNN(VGG16) 모델을 비교했다. PASCAL VOC 데이터셋으로 학습시켰으며 보행자(person) 이외의 class는 고려하지 않았다. Tracking시에는 probabilities가 50%이상인 bounding box만 사용했다.
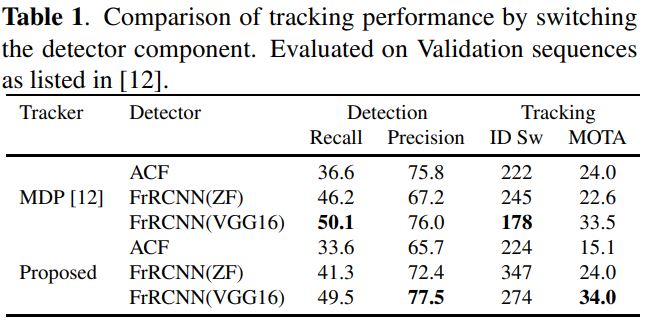
ACF모델과 비교하면 FrRCNN 모델이 현저히 높은 성능을 보인다. SORT와 또다른 online tracker인 MDP에 사용되었던 데이터셋을 활용해서 그 성능을 증명했다. 결론은 FrRCNN(VGG)가 SORT와 MDP에서 최고의 성능을 보인 Detector이다.
2. Estimation Model
Tracking을 하는 과정에서 다음 frame에 전달되어야 하는 각 target들의 정보(ID정보)를 모델링하는 Object Model(또는 motion model)를 표현했다. 저자는 각 object에 대한 frame간의 변위(object가 이동한다고 할 때)를 각각의 object와 camera motion에 독립인 선형 등속도 모델(linear constant velocity model)을 통해 근사했다. 각 object은 다음과 같이 표현한다.
ratio는 모든 object에 대해 동일한 값을 사용을 했다. 만약 detection(bounding box)이 target(기존에 존재하던 tracks)과 association이 되면 해당 bbox에 대응되는 target의 state(velocity components)가 업데이트된다. 이때 velocity components는 Kalman Filter에 의해 계산된다. 반대로 detection에 대해 association이 발생하지 않으면 target의 state는 보정되지 않고 단지 선형 등속도 모델로 간단히 예측만 이루어진다.
Detections이 target과 association이 이루어질 때 detection의 bbox와 kalman filter로 예측된 target의 bbox가 보정을 통해 업데이트된다.
3. Data Association
약간 기술적인 내용이 많아서 이해를 위해 각 단어를 정의하고 설명하는 것이 좋을 것 같다.
- target : 기존에 tracking되고 있던 object
- bounding box geometry(bbox geometry) : bbox에 대한 좌표값 및 스케일, 비율
- detection : 현재frame에서 detector를 적용한 결과
Detection이 각 target에 할당되는 과정은 다음과 같다. 먼저 각 target들은 직전frame에서 현재frame에서의 location인 bbox geometry(A)를 예측한다. 그리고 detection된 모든 object들과 (A)를 IOU(Intersection-over-Union) 차이(distance)를 통해 assignment cost matrix를 계산한다. cost matrix에 Hungarian algorithm을 적용하여 대응되는 detection과 target을 매칭한다. 추가적으로 IOU의 임계값($IOU_{min}$)을 넘지 못하면 assignment가 발생하지 않도록 하는 장치도 설정했다.
IOU distance가 short-term occlusion을 해결한다고 하는데, 해당 부분이 이해가 가지 않아서 원본을 그대로 가져왔다.(3.3 마지막 문단)
We found that the IOU distance of the bounding boxes implicitly handles short term occlusion caused by passing targets. Specifically, when a target is covered by an occluding object, only the occluder is detected, since the IOU distance appropriately favours detections with similar scale. This allows both the occluder target to be corrected with the detection while the covered target is unaffected as no assignment is made.
이해를 완료했기 때문에 설명을 하면 다음과 같다.
IOU distance가 short-term occlusion을 해결한다고 한다. 크기가 서로 다른 두 사람이 겹치지는 상황을 가정해보자. (N)frame에서 두 사람이 겹쳐졌을 때, (N-1)frame에서부터 kalman filter에 의해 예측된 target 2개는 (N)frame에서 겹쳐져 있을 것이다. 하지만 이때 Detection이 이루어지면 (만약 큰 사람이 앞에 있다면) 큰 사람만 detect가 되고, 작은 사람은 occlusion가 발생하여 detect되지 않는다. 이후에 (n+1)frame에서 다시 찢어지게 됐을 때 비로소 2명 모두가 detect 될 것이고, target도 kalman filter에 의해 2개의 target이 예측될 것이다. 이때 detection과 target을 association을 하기 위해서 유사성을 계산해야하는데, 이때 사용되는 지표가 IOU distance이다. IOU distance는 비슷한 scale의 bbox에 대해 favours하기 때문에 크기가 다른 두 detection과 target에 대해 효과적으로 association을 할 수 있다. 따라서 비록 occlusion가 발생했더라도 IOU distance의 ‘scale favours’한 특징 덕분에 ID Switch없이 잘 탐지할 수 있다.
하지만 크기가 비슷하면 무용지물이다. 근데 사람의 크기는 멀리서 보면 대부분 비슷하다....
4. Creation and Deletion of Track Identities
이미지 내에 object가 들어오고 나갈 때 각 object에 유니크한 ID를 부여하고 삭제한다. 먼저 ID를 부여할 때는 다음과 같은 특징을 가진다.
- detections에 있는 object 중 모든 target과의 IOU값이 $IOU_{min}$보다 작은 object들이 대상이 된다.
- 해당 target(tracker)의 velocity는 0으로 초기화된다.(Kalman Filter에 사용될 요소)
- 탐지된 순간에는 velocity 관측값이 없기 때문에 불확실성에 의해 velocity의 공분산도 매우 커진다.
- 새로운 target(tracker)은 false positive(FP)를 방지하기 위해 수습기간을 거쳐 evidence를 모은다.
- 모인 evidence를 이용해 detections과 association해야하는지 판단한다.
삭제는 다음과 같은 특징을 가진다.
- $T_{Lost}$ frames동안 특정 target에 대해 Detection이 이루어지지 않으면 해당 target은 삭제된다.
- Detector의 보정 없이 계속 추적하는 tracker의 무분별한 증가를 방지하기 위해 삭제한다.
- lost target를 빠르게 삭제하면 모델의 효율이 증가한다.
- $T_{Lost}$는 1로 설정했는데, 2가지 이유가 있다.
- constant velocity model은 역학에 있어서 매우 빈약한 예측변수이다.
- frame-to-frame tracking 방식에 초점을 두기 때문에 Re-Identification은 관심 밖이다.
- 만약 일정시간 후에 같은 obejct가 다시 등장한다면, 새로운 ID를 부여한다.
Experiments
SORT를 평가하기 위해 다양한 종류의 데이터셋과 이동식과 고정식 카메라에 대한 데이터셋이 모두 포함되어 있는 MOT benchmark databse를 이용했다. 초기 Kalman Filter covariance값과 $IOU_{min}$, $T_{Lost}$파라미터를 튜닝하기 위해 [12]논문과 같은 training/validation셋을 이용했다. Detector는 FrRCNN(VGG16)을 사용했다.
Metrics
한 가지 요소로 Tracking 모델의 성능을 평가하기는 쉽지 않다. 그래서 다양한 MOT metrics를 사용했다.
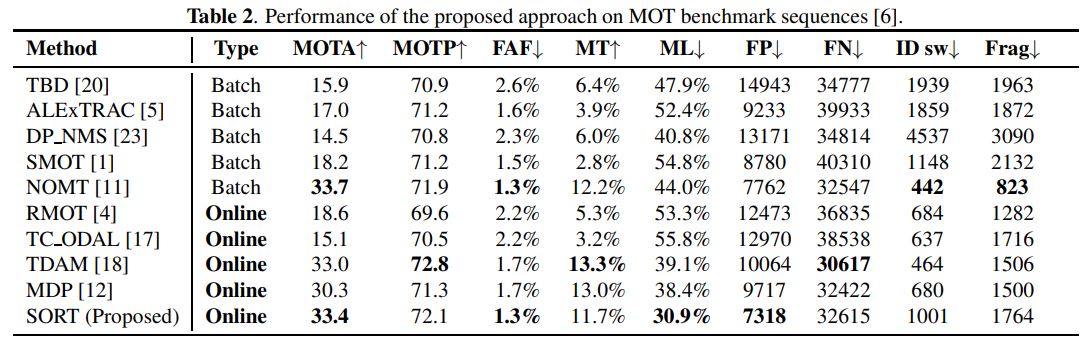
- FAF(↓): number of false alarms per frame.
- MT(↑): number of mostly tracked trajectories. I.e. target has the same label for at least 80% of its life span.
- ML(↓): number of mostly lost trajectories. i.e. target is not tracked for at least 20% of its life span.
- FP(↓): number of false detections.
- FN(↓): number of missed detections.
- ID sw(↓): number of times an ID switches to a different previously tracked object.
- Frag(↓): number of fragmentations where a track is interrupted by miss detection.
각 성능지표들에 대해서는 따로 포스팅을 할 예정이다.
Conclusion
- frame-to-frame을 위한 간단한 online tracking framework를 소개했다.
- MOT의 성능은 Detection의 성능이 좌지우지한다는 것을 보였다.
- 전통적인 Tracking method를 이용해 SOTA급 성능을 보였다.
- 다른 모델들과 달리 정확도와 속도의 Trade-off 관계를 부셔버렸다.(둘 다 성능 좋음)
- 다른 method를 결합하기 쉽도록 baseline을 구현했다.
MOT 분야의 대표적인 모델인 SORT에 대해 알아보았다. 논문을 통해서 많은 사실을 배울 수 있었는데, 특히 Tracking이 어떤 원리를 이용해 이루어지는지 정확하게 파악할 수 있었던 계기가 되었다. 또 SORT 자체의 코드를 확인해보면 매우 간단한 것을 알 수 있는데, Conclusion에서도 언급했듯이 다른 method를 쉽고 빠르게 결합해 볼 수 있을 것 같다. 전통적인 Tracking 기법인 Kalman Filter와 Hangarin Algorithm에 대해서도 포스팅을 할 예정이다.