Multi Object Tracking에 대해 전반적으로 알 수 있는 논문인 Multiple Object Tracking: A Literature Review를 읽고 간단히 정리해보았다.
Abstract
MOT 테스크를 수행하기 위해 많은 방법들이 시도 되었는데, 여전히 Abrupt Appearence change(갑작스러운 변화)와 Ojbect Occlusions(물체 폐색) 등의 문제가 발생하고 있다. 따라서 이 논문에서는 이러한 문제를 다뤄볼 예정이다. 그리고 가장 최신의 기술들을 리뷰해볼 예정이다.
Introduction
MOT는 각 물체의 위치를 찾고 ID를 부여하며 영상으로부터 해당 물체의 궤도를 산출한다. 물체는 다양한 것이 있지만, 이 논문에서는 Pedestrain(보행자)에 대해서만 집중적으로 다뤄볼 예정이다. 그 이유에는 3가지가 있다.
- 보행자는 보통 멈춰있지 않기 때문에 MOT 연구에 적합하다.
- 보행자 데이터로부터 많은 경제적 이익을 얻을 수 있다.
- 전체 데이터의 70% 정도가 보행자에 대한 데이터이다.
MOT를 기초로한 high-level 테스크로는 pose estimation, action recognition, behavior analysis 등이 있다. 실제로 MOT가 사용되는 곳은 감시, Human computer interaction, VR 등이 있다.
스케일 변화와 out-of-plane 회전, 조명 변화 등을 해결하기 위해 정교한 모델을 만드는데 중점을 둔 SOT(Single Object Tracking)와 다르게 MOT는 두 가지 테스크를 해결해야 한다. 시간에 따른 물체의 개수와 각각의 IDs.
또한 MOT의 경우 빈번한 폐색 현상과 추적하던 물체의 출현과 사라짐, 비슷한 물체, 그리고 물체들끼리의 interaction 등의 문제가 발생한다. 이러한 문제를 해결하기 위해 오랜 기간 연구가 되어왔다.
이 논문을 통해 이러한 문제를 해결할 수 있는 다양한 방법들에 대해 소개하고자 한다.
1.1 다른 리뷰 논문과 다른 점
MOT에 대해 포괄적으로 다룬 논문은 없지만, 비슷한 리뷰 논문은 있다. 이 중에 **‘MOT Benchmark(2015)’라는 survey는 읽어볼만 하다.
1.2 기여
이 논문이 main challenges, pitfalls, start of the art를 이해하는데 도움이 될 수 있다.
- 대부분의 MOT 메소드를 아우르는 formulation을 이끌어내고, 메소드는 크게 2가지로 분류한다.
- 원리, 장점, 단점 등에 관한 키포인트를 다양한 측면으로 얘기함
- 다양한 접급법과 데이터셋에 대한 실험 결과를 제시
- MOT 리뷰를 통해 연구의 이슈에 대해 다룬다.
L. Leal-Taixe, A. Milan, I. Reid, S. Roth, and K. Schindler, “MOThallenge 2015: Towards a benchmark for multi-target tracking,” arXiv preprint arXiv:1504.01942, 2015. 이거 읽어보는거 추천함
MOT Problem
MOT의 일반적인 수학 공식에 대해 내용과 다양한 측면에 대한 분류에 대해 얘기한다.
2.1 Problem Formulation
연속적인 이미지(Video)가 있을 때, $s_t^i$는 $t$번째 frame에 있는 $i$ object이다. 따라서 $S_t = (s_t^1, s_t^2,…,s_t^{M_t})$는 $t$번째 frame에 있는 $M_t$의 object을 표현했다.
수학 수식….
2.2 MOT Categorization
특정 MOT메소드를 보편적 기준으로 나누기는 힘들다. 그래서 논문에서는 a) Initialization method, b) Processing mode, Type of output로 분류했다. 3가지로 분류한 이유는 MOT 테스크가 위 방식대로 흘러가기 때문이다.
2.2.1 Initialization Method
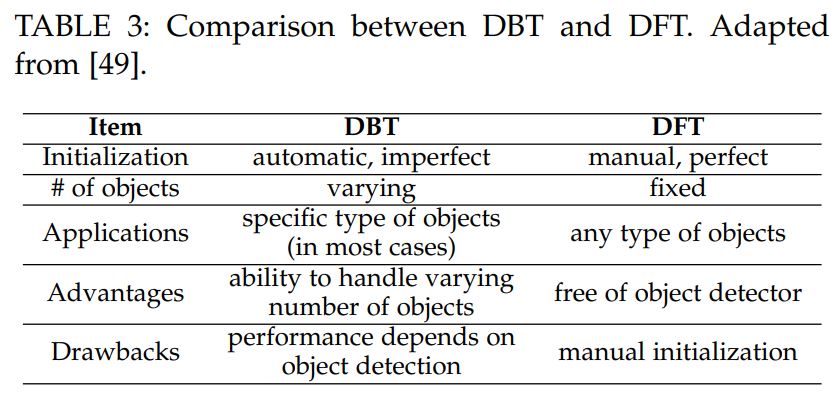
MOT는 어떻게 Initialization을 하느냐에 따라 크게 2가지로 분류되는데, Detection-Based Tracking(DBT)과 Detection-Free Tracking(DFT)가 있다.
Detection-Based Tracking의 경우 처음에 Object Detector 모델을 이용해 Detection을 수행한 후 Trajectories에 링크된다. 따라서 Tracking-by-Detection이라고도 불린다. 매 frame마다 detector가 물체를 detection한다.
- Detector가 사전에 학습된 모델이기 때문에 DBT는 보행자, 차량 또는 얼굴과 같이 특정 유형에 초점을 맞춘다.
- DBT의 성능은 Object Detector의 성능에 큰 영향을 받는다.
Detection-Free Tracking의 경우 첫 frame에서 수동으로 object를 설정하고 이후에 오는 frame에서 object를 localize한다.
보통 DBT가 더 많이 사용된다. 이유는 DFT의 경우 새로운 object에 대해서는 탐지하지 못하기 때문이다.
2.2.2 Processing Mode
Tracking을 하는데는 2가지 방법이 있다. 이전 Frame의 정보만 이용해 현재의 Frame을 분석하는 Online-Tracking(causal)과 과거와 미래 Frame의 정보를 이용해 현재 Frame을 분석하는 Offline-Tracking(batch tracking)이다.
Online-Tracking(Sequential Tracking)의 경우 Step-wise(차근차근) 방식을 사용한다. 직전의 Frame에서 관찰된 정보를 이용해 연산을 진행하면서 궤적(object가 이동한 길)을 계산한다.
Offline-Tracking(Batch Tracking)의 경우 배치 단위의 Frame을 이용한다. 사전에 모든 Frame을 확인한 후에 마지막 output의 물체를 연결짓는다. 과거 뿐만 아니라 미래의 데이터도 모두 활용해서 분석을 한다. 하지만 계산량이 많아지고 메모리 부족 현상이 발생하기 때문에 전테 Frame을 전부 이용하지 않고 부분을 잘라서 사용한다.
2.2.3 Type of Output
결과값의 무작위성에 의해 MOT는 2가지로 분류된다. 결정론적 방법은 여러 번 실행을 해도 항상 같은 결과가 나온다. 반면 확률론적 방법은 실행마다 다른 결과가 나온다.

2.2.4 Discussion
- DBT와 DFT의 차이는 Detection의 유무에 의해 구별된다.
- Online과 Offleine의 차이는 Observation을 처리하는 방법에 의해 구별된다.
Sequentially하게 처리를 하는 DFT와 Online Tracking이 동일하다고 생각할 수 있지만, ‘Orderless Tracking’과 같은 예외는 존재한다. 비록 SOT지만 MOT로 사용할 수도 있고, Batch mode로도 가능하다. DBT 또한 매우 모호하지만 이전 Obtained과 새로운 Obtained과의 궤적을 Sequential하게 처리하는 경우도 있다.
3. MOT Components
이 장에서는 MOT의 Approach에 대해 언급할 예정이다. MOT의 목표는 여러 objects를 Frame마다 탐지하고 ID를 부여하며 Trajectory를 산출한다.
- 여러 Frames에 대해서 어떻게 object들의 유사성을 측정할 것인가?
- 유사성을 기초로 어떻게 ID를 구여할 것인가?
첫 번째 경우는 apperance, motion, interaction, exclusion, occlusion 등의 Modeling 작업이고, 두 번째는 Inference Probelm이 포함된다.
3.1 Appearance Model
Appearance Model은 MOT에서 연관성을 계산하는데 사용된다. 하지만 배경과 물체를 구분하기 위해 정교한(Sophisticated) appearance modeling을 하는 SOT와는 다르게 MOT에서는 appearance modeling을 중요한 요소로 다루지 않는다.
Appearance Model은 2가지 요소가 있다.
- visual representation : 물체의 특징을 표현하는 방법으로 1개 또는 2개 이상의 feature를 이용한다.
- statistical measuring : 두 물체간(i,j)의 유사성을 측정한다.
$o_i$와 $o_j$의 경우 서로 다른 object의 visual representation를 나타내고 $F()$는 유사성을 측정하는 함수이다.
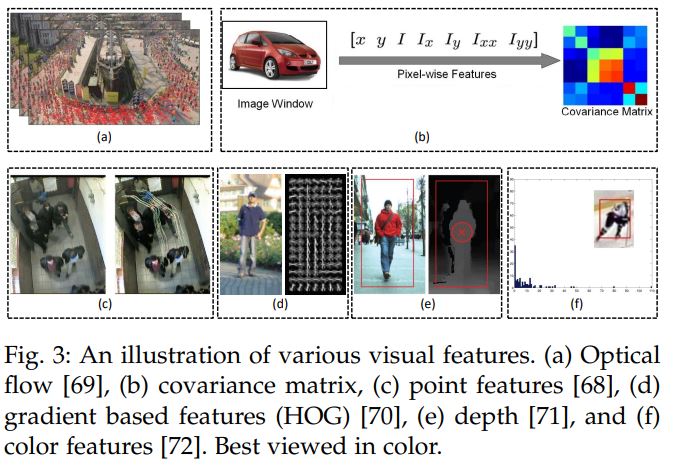
3.1.1 Visual Representation
여기서 Visual representation 이미지에서 추출할 수 있는 feature들을 말한다.
Local Features은 물체 자체내에서 추출하는 feature로 대표적으로 KLT(Kanade–Lucas–Tomasi)가 있다. SOT와 MOT 두 곳 모두에서 사용되는 Feature로 좋은 성능을 보인다. easy-to-track features를 이용하여 짧은 궤적을 산출하거나 카메라 모션, 모든 클러스터링 등을 할 수 있다. Optical Flow도 역시 feature 중 하나다. 보통 MOT 솔루션에서 association하기 전 detection을 link하는 과정에서 사용된다. Optical Flow는 Crowded한 상황에서 뛰어난 성능을 발휘한다.
Region features은 Local Features보다 좀 더 광범위하게 추출되는 feature로 Global Feature라고도 한다. 그리고 이미지 내에서 픽셀값들의 차이를 몇 번 계산했냐에 따라 단계별로 나눠진다.
- zero-order : 픽셀의 차이를 사용하지 않음. Color Histogram이 대표적
- First-order : 픽셀의 차이를 한 번 계산함. HOG와 level-set formulation가 있음.
- Up-to_second-order : 픽셀의 차이를 2번 계산. Region Covariance Matrix가 대표적
이 밖에도 예측된 detection을 정제하거나 object가 특정 grid cell에 존재하는 것을 확률로 나타내는 POM(Probabilistic Occupancy Map) 등의 feature도 있다. 보행자에 대한 feature로 gait feature도 있다.
Color Histogram은 유사성에 대한 연구는 잘 되었지만 공간특성을 무시하고, Local feature는 효과적이지만 occlusion과 out-of-plane rotation에 약함. 기울기를 기초로한 HOG의 경우 illumination에 robust하지만 occlusion과 deformation(변형)에 약함. Region convariance matrix feature의 경우 매우 robust하지만 얻어진 정보만큼 계산량이 많아진다. depth feature(부피 관련 feature)는 유사성을 더 정확히 계산하지만, Depth를 구하기 위한 다양한 각도의 view와 알고리즘이 필요하다.
3.1.2 Statistical Measuring
위 내용과 연관이 큰데, 통계학적 계산은 두 observation에 대한 유사성을 계산한다. Single 과 Multi cue가 있다.
두 observations의 거리를 유사성으로 변환하거나 직접적으로 유사성을 계산하는 것이 Single cue을 이용한 Modeling appearance이다.
- NCC(Normalizaed Cross Correlation) : row pixel template(아마도 Region Features에 zero-order를 말하는 듯)을 기초로 두 observations에 대한 유사성을 계산.
- ‘Bhattacharyya distance($B(.,.)$)’ : $c_i$와 $c_j$가 두 Color Histogram이라고 하면 거리는 다음과 같은 식에 의해 유사성으로 변환된다.
- 가우시안 분포를 이용해 거리를 계산
- 비유사성을 likelihood로 변환하는 것도 공분산의 표현으로 사용.
- bag-of-words 모델도 point feature representation을 기초로하여 사용
서로 다른 두 요소들이 서로 보완하며 더 robust한 appearance model를 만드는 것을 Multiple cues 방식이다. 이러한 Multi cue를 합치는 방식을 5가지로 요약했다.
- Boosting : Boosting 기반 알고리즘을 이용해 feature를 선택하는 방식. Color Histogram, HOG, Convariance Matrix 등이 있을 때 AdaBoost, RealBoost 등을 이용해 같은 object에 대한 tracklets를 구별한다.
- Concatenation : 여러 features를 연결하여 appearance model를 만든다.
- Summation : 서로 다른 feature에서 유사한 value를 추출한 후 weight를 적용하여 합친다.
- Product : 위 전략과 다르게 하나의 유사성으로 통합하기 위해 features를 곱한다.
- Cascading : visual representation의 다단계 방식을 이용
3.2 Motion Model
Motion Model은 object에 대한 미래 frame에서의 잠재적 position을 계산함으로써 탐색 공간을 줄인다. 대부분의 object는 smooth하게 움직인다.
3.2.1 Linear Modtion Model
등속도 추정 모델도 Linear Motion Model을 통해 만들어졌다. 등속도 추정 모델은 3가지 다른 방식으로 수행된다.
- Object의 속도 변수를 연속적인 frame에 대해 smooth하도록 강제하여 velocitiy smoothness를 모델링한다.
- 관측된 position을 중심으로 예측된 position이 가우시안 분포를 따르도록 하여 Postion smoothness를 모델링한다.
- Acceleration smoothness 또한 고려해야하는 요소 중 하나이다.
3.2.2 Non-Linear Motion Model
Linear motion model로 물체의 역학을 설명할 수 있지만, 물체가 자유롭게 이동하는 경우에는 불가능하다. 그때는 물체간의 유사성을 정확하게 계산하기 위해 non-linear가 사용된다.
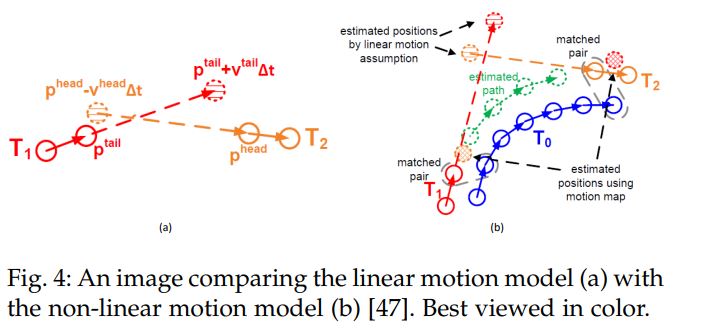
도저히 무슨 내용인지 이해가 가지 않습니다….도움이 필요합니다.
3.3 Interaction Model
Mutual motion model이라고도 불리는 Interaction model은 object간의 영향을 포착한다. 예를 들어 사람이 길을 걷다가 장애물이 있거나 다른 사람이 있으면 속도를 조절하거나 방향을 바꾼다. 또 사람이 많은 곳에서 길을 걸을 때 다른 사람들을 따라가는 경향이 있다. 이렇게 두 물체 간의 영향(force)을 표현한 모델에는 대표적으로 2가지가 있다.
3.3.1 Social Force Models
각 object들은 서로 영향을 주는데, 이에 대한 정보는 복잡한 상황(crowded scenes)에서 발생하는 성능저하를 완화시켜준다. social force model에서는 각 object들의 행동은 2가지 측면에 의해 모델링된다.
- 개인의 영향(individual force) : 여러 object가 존재하는 그룹 속에 각 object들은 ‘object가 목표로 하는 목적지는 바뀌지 않는다’는 fidelity와 ‘object는 속도나 방향 등을 갑작스럽게 바꾸지 않는다’는 constancy이 고려된다.
- 단체의 영향(group force) : ‘뭉쳐서 다니는 사람들은 서로 가까이 있어야 한다’는 attraction과 ‘뭉쳐 다니는 사람들은 다른 무리들과의 거리를 둔다’는 repulsion, ‘뭉쳐서 다니는 사람들은 모두 비슷한 속도로 움직이다’는 coherence가 고려된다.
social force를 이용해 object간의 상호작용을 모델링하는 대부분의 publications는 individual과 group force를 반영해 energy objective를 최소화한다.
3.3.2 Crowd Motion Pattern Models
object들의 밀집도가 높은 복잡한 상황에서 tracking하는데 사용된다. 보통 복잡한 상황(highly-crowded scenery)에서는 object들이 매우 작고 각 object들의 특징들이 모호하다. 따라서 이러한 상황에서는 군중의 motion 패턴은 좋은 특징이 된다.
대략 2가지가 있는데, ‘structured’와 ‘unstructured’이다. 전자는 집단 시공간적인 구조(spatio-temporal)를 보이고, 후자의 경우 모션의 다양한 양식(modalities of motion)을 보인다. 아래와 같이 다양한 메소드를 통해 motion pattern를 산출하고 tracking하기 전 사전 정보로 사용된다.
- ND tensor votiong
- Hidden Markov Models
- Correlated Topic MOdel
3.4 Exclusion Model
배제는 MOT에서의 문제를 해결하는 방법을 찾을 때 물리적 충돌을 피하기 위한 제약 조건이다. 같은 물리적 공간에 서로 다른 두 object가 존재할 수 없다는 사실에 기반한다.
3.4.1 Detetction-level Exclusion modeling
서로 다른 두 detection이 같은 frame 안에서 같은 target을 할당하지 못하도록 제약 조건을 거는 model이다. ‘soft’와 ‘hard’한 방식이 있다.
- Soft modeling : 같은 frame 안에 두 detection 반응이 있을 때 같은 trajectory를 할당하면 증가하는 cost를 최소화하는 방식이다.
- Hard modeling : 명시적으로 제약 조건을 건다. 두 tracklets가 같은 frame 안에서 겹치면 같은 trajectory로 할당하지 않는다.
3.4.2 Trajectory-level Exclusion Modeling
비슷한 두 개의 detection hypothese가 있을 때 다른 trajectory label라고 인식했을 때 패널티를 주는 방식이다. 즉, 한 가지 trajectory로 표현된다. 두 개의 detection과 두 개의 trajectory label가 반비례하는 패널티를 정의하여 두 detection이 비슷하면 cost가 증가하는 방식으로 작동한다.
3.5 Occlusion Handling
ID스위치나 trajectory를 파괴하는 주범인 Occlusion은 MOT의 가장 큰 문제 중 하나이다. 이 문제를 해결하기 위해 다양한 전략이 존재한다.
3.5.1 Part-to-whole
대부분 이 방식을 사용한다. object가 occlusion이 발생했을 때 object의 일정 부분이 보인다는 가정 하에 실시된다. 가장 흔히 사용되는 방식은 다음과 같다.
전체 object(bbox 부분)를 여러 조각으로 나눈 후 occlusion되었을 때 각각의 부분의 유사성을 계산한다. 이때 occluded된 부분의 유사성은 매우 낮을 것이고, tracker가 이 사실을 인지하고 unoccluded된 부분만 estimation한다. 특히 object들을 여러 조각으로 나눌 때는 grid를 통해 만들어지거나 사람의 체형에 맞게 fitting된다. Reconstructed error에 의해 어느 part가 occlusion되었는지 판단하고, appearance 모델은 unocclusion된 부분만을 udpate한다. 이처럼 ‘hard’한 방식이 있는 반면, ‘soft’한 방식도 있다. 두 개의 tracklets($i, k$)가 있을 때 $\sum_i{w_iF(\text{f}^i_j, \text{f}^i_k)}$를 계산한다. $\text{f}$는 feature, $i$는 나눠진 파트의 index이다. weight의 경우 나눠진 파트별 occlusion relationship에 의해 학습된다.
3.5.2 Hypothesize-and-test
이 전략은 가설을 세우고 testing 하면서 occulsion을 방지할 수 있는 방법을 찾는 것이다. 서로 가깝고 비슷한 스케일을 가진 occlusion된 두 observation에 대해 occlusion hypotheses를 설정한다. $o_i$이 $o_j$에 의해 occulsion되었다고 가정하면 occulsion hypotheses는 $\tilde{o_i} = (p_j, s_i, \text{f}_i, t_j)$가 된다. $p_j$와 $t_j$는 $o_j$에 대한 position과 time stamp이고 $s_i$와 $\text{f}_i$는 $o_i$의 size와 appearance feature가 된다. coclusion pattern은 occlusion이 발생한 상황에서 detection을 하는데 도움을 준다. 서로 다른 detection은 occlusion의 정도와 패턴에 따라 나눠진다.
3.5.3 Buffer-and-recover
occlusion이 발생하면 observations를 buffer로 저장하여 occlusion가 끝나면 buffer를 이용해 recover하는 방식이다. Occlusion가 발생가 발생했을 때 특정 frame동안은 trajectory가 생존할 수 있도록 저장. tracking state가 모호해지면 obseravation mode를 활성화시킨다.
3.6 Inference