Mask-RCNN은 2017년 Mask R-RCNN이라는 논문을 통해 발표되었다. 논문 제목에서도 알 수 있듯이 모델에 대한 자부심이 강한 것 같다. 비슷한 이름을 많이 본 것 같은 느낌이 드는데, RCNN부터 Fast,Faster-RCNN 등 시리즈별로 존재한다. 시리즈답게 기본 베이스는 Faster-RCNN을 사용했다고 한다. 또한 Object Detection이 아닌 Segmentation을 목적으로 하는 모델이다.
0. Abstract
Mask-RCNN은 매우 간단하고 flexible하며 매우 높은 성능을 보이는 Instance Segmentation 모델이다. 물체의 bouning box를 예측하는데 약간의 overhead만 추가한 Faser-RCNN을 사용했다. Mask-RCNN은 Segmentation 이외에 human pose estimation을 하는데도 활용할 수 있다. 마지막으로 COCO 2016년 우승 모델을 포함하여 그 당시에 현존하는 모든 모델보다 성능이 좋았다.
1. Introduction
Object Detection과 Segmentation 분야는 급속도로 발전했다. Fast/Faster RCNN과 FCN 같은 flexible하고 robust하며 train과 inference가 빠른 모델 등이 있었는데, 우리 연구의 목표는 이러한 모델을 포함하여 Instance segmentation의 모델을 발전시키는 것이다. 하지만 instance segmentation은 매우 어렵다. 왜냐하면 각 물체별로 위치와 bbox, 더 나아가 픽셀 단위로 분류까지 진행해야하기 때문이다. 심지어 semantic과 다르게 instance는 각 객체별로 구분도 지어야한다. 하지만 Mask-RCNN은 그 당시에 간단하고 빠르며 SOTA를 넘기는 성능을 보여줬다.
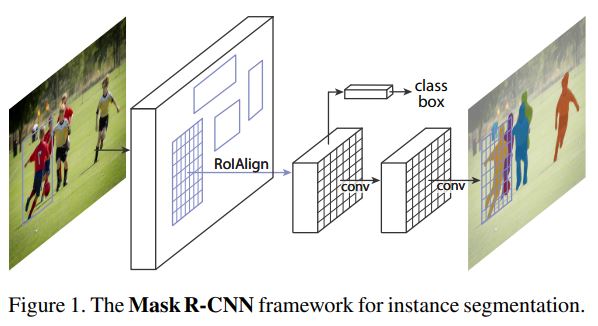
Mask-RCNN은 Faster-RCNN모델을 기반으로 ‘각 Roi(Region of Interest)에 대해 Segmentation mask를 예측하는 부분’과 ‘classification과 bbox regression하는 부분’이 병렬적으로 연결되어 있다. mask의 경우 픽셀 단위로 예측하는 FCN의 소형버젼을 이용했고, Faster-RCNN가 주어진다면 Mask-RCNN은 매우 간단하게 구현할 수 있다.
하지만 Faster-RCNN의 경우 해당 모델의 핵심 부분은 RoIPooling 부분을 보면 알 수 있듯이 feature extraction을 할 때 상대적으로 조밀(coarse spatial)하게 추출하지 못하기 때문에 pixel-to-pixel에는 적합하지 않다. 따라서 이러한 문제를 해결하기 위해 추가적인 조밀한 정보를 얻을 수 있는 RoIAlign이라는 간단한 기법을 제안했다. 작은 변화지만 mask성능에는 큰 영향을 미쳤다.(10% -> 50%) 또한 연구를 통해 mask와 classification를 분리해야한다는 사실도 발견했다. mask의 경우 class별로 독립적으로 binary mask를 구했고, class의 경우 네트워크의 RoI classification을 통해 예측을 했다. 반면에 FCNs모델의 경우 픽셀별로 multi-class를 분류하기 때문에 결론적으로 실험에 의해 두 테스크를 합치면 성능이 좋지 않았다는 사실을 확인했다.
- Without bells and whistles, COCO instance segmentation분야에서 SOTA를 넘었다.
- Mask-RCNN은 GPU을 사용하면 200ms/frame의 속도가 나오고 8-GPU 머신을 이용해 COCO 데이터를 학습하는데 약 1~2일이 걸린다.
- COCO key-point dataset을 이용해 Human pose estimate하는 분야에서도 좋은 성능을 보였다. 단순히 mask를 one-hot binary mask 테스크로 변경해서 구현했다.
2. Related Work
R-CNN 시리즈
R-CNN은 수많은 object의 후보군인 Region Proposal을 추출해 각각의 RoI에 대해 classification과 bbox를 구한다. 이후에 RoIPooling 기법의 도입으로 속도가 향상되었고, Faster-RCNN에서 Region Proposal Network(RPN)을 통해 더욱 발전시켰다. Faster-RCNN은 여전히 많이 사용되고 있다.
Instance Segmentation
대부분의 모델이 R-CNN에 영감을 받아 Segment Proposals를 기반으로 설계되었다.(마치 Region Proposals 처럼) Proposals들은 이후에 Fast R-CNN에 의해 분류되는 과정을 거쳤다. 하지만 이러한 방법은 매우 느리고 성능이 좋지 않았다. Mask-RCNN은 mask과 class label의 classification을 parallel(병렬)하게 처리함으로서 더 간단하고 flexible하다.
가장 최근에 Object detection과 Segment proposal system을 합친 FCIS(Fully Convolutional instance segmentation)모델을 발표했는데, 아쉽게도 겹쳐져있는 물체들에 대해서 잘 분류하지 못했다. 또다른 시도로는 FCN의 결과(픽셀단위 classification)에서 같은 class의 픽셀을 달라내 classification을 시도했다.(segmentation-first strategy)
Mask-RCNN은 instance-first 방식을 사용했다.
3. Mask-RCNN
Mask-RCNN의 컨셉은 간단하다. Faster-RCNN은 2개의 output(bbox와 class label)를 출력하는데, 그 결과에 3번째 output인 object mask를 추가했다. 하지만 mask는 bbox, class label과 분리되기 때문에 좀 더 finer한 spatial loayout이 필요하다. 그리고 Fast/Fatser-RCNN에는 없는 pixel-to-pixel alignment를 추가했다.
Fatser-RCNN
Faster-RCNN은 2-stage로 구성되어 있다. 첫 번째로 Object의 bbox후보군을 추출하는 Region Propsal Network(RPN)부분과 RoIPool을 이용해 bbox후보군으로부터 feature를 추출하고 classification과 bbox regression을 계산하는 부분이 있다.
Mask-RCNN
Mask-RCNN또한 2-stage로 구성되어 있다. 첫 번째는 위와 동일하게 RPN부분이다. 두 번째는 각 RoI에 대해 class와 bbox offset, binary mask를 병렬적으로 추출한다. mask의 예측에 따라 class가 달라지는 기존 방법과 대조적이다.(instance-fisrt strategy) 또한 bbox-classification과 regression은 기존 R-CNN에서 했던 방식과 동일하게 병렬적으로 수행했다.
Training을 할 때는 다음과 같은 Loss를 정의했다.
$L_{cls}$와 $L_{box}$는 기존 Fast-RCNN에서 정의한 Loss와 동일하다. Mask의 경우 각 RoI별로 $Km^2$-dimension을 가지고, $K$는 binary mask의 개수를 뜻하고 $m$은 K개의 class별 mask의 사이즈($m$ x $m$)을 말한다.
Mask에 대한 $L_{mask}$는 average binary cross-entropy loss로 정의했다. 각 RoI에 대해 픽셀별로 sigmoid를 적용하고, 대응하는 정답 class k와 이에 대응되는 k-th의 mask만 사용하여 두 사이의 loss를 구했다. 다른 mask는 관여하지 않는다.
본 연구에서 정의한 $L_{mask}$는 classes간의 경쟁 없이 class별로 mask를 생성하도록 네트워크를 학습시킨다. 출력된 mask들에 대응하는 class label를 예측하기 위해 classification branch에 의존하고, 이것은 곧 mask와 class prediction의 분리를 의미한다. 이 방식은 기존 FCNs와 차이가 있는데, class의 개수만큼 feature map이 출력되고 픽셀별로 softmax를 적용해 multitional cross-entropy loss를 사용하는 FCNs과 차이가 있다. 실험을 통해 분리된 방식이 더 좋다는 것을 증명했다.
Mask Representation
Mask는 입력데이터(input)를 class label이나 bbox의 offset처럼 vector로 축소되기 보다는 CNN에 의해 각 픽셀별(Pixel-to-Pixel)로 대응할 수 있는 spatial layout을 출력한다. 마치 FCNs처럼 각 ToI에 대해 $m$ x $m$ 사이즈의 mask를 예측한다. 이러한 결과는 공간 정보(spatial-dimension)를 유지하는데 도움을 준다. 다른 모델들과 다르게 적은 파라미터로 더 좋은 성능을 보였다.
Pixel-to-Pixel를 실현하기 위해서는 RoI Feature에 의해 공간 정보(Spaital)가 보존되어야하는데, 이런 역할을 돕기 위해 RoIAlign을 개발했다.
RoIAlign
RoIPool은 RoI로부터 작은 feature map을 생성하는 연산이다. 먼저 RoI(offset)의 소수점을 버림으로서 이산적으로 만든 후 특정 bin의 크기(2x2, 7x7 등)만큼 구역으로 나눠서 pooling layer가 적용된다.(ex. MaxPool) 이런 이산화 과정에서 RoI와 추출된 feature의 misalignment가 발생한다. classification문제에서는 괜찮지만, pixel-to-pixel처럼 정교한 테스크에는 부정적인 영향이 크다.

위 그림은 2x2 bins로 RoI를 나눈 상황으로 가정을 한다. 점선으로 표시한 gird는 feature map에 해당하고 검은색 실선은 RoI를 뜻한다. RoI 안에 나눠진 구역(2x2)에 가로, 세로 균등한 간격으로 4개의 점을 찍는다. 그리고 각 점에서 가장 가까운 픽셀값 4개로부터 bilinear interpolation를 적용해 픽셀값을 할당한다. 마지막으로 Pooling layer를 적용한다.
Network Architecture
크게 2가지 파트로 나눴다.
- feature를 추출하는 CNN기반의 backbone
- bounding-box recogntition(classification, regression)과 Mask를 예측하는 head
backbone 부분을 ‘network-depth-feature’로 명명했다. ResNet과 ResNeXt 두 가지 모델에 대해 비교를 했었다. Fatser-RCNN은 ResNet을 backbone으로 사용했는데, 보통 4번째 layer의 출력값인 C4를 feature로 사용했다. 따라서 backbone을 ResNet-50을 사용한다는 것은 ResNet-50-C4를 뜻한다. 또다른 모델인 Feature Pyramid Network(FPN)를 시도했는데, 매우 효과적이었다. FPN은 CNN의 각 stage마다 feature map을 추출하여 하나의 feature map으로 합친 후 예측을 하는 모델이다. 다양한 scale의 feature map을 얻을 수 있어서 성능이 좋다. 최종적으로 ResNet-FPN을 backbone으로 사용했을 때 가장 빠르고 정확했다.
네트워크의 head부분은 두 가지 버젼이 있다. ResNet-C4와 ResNet-FPN에 따라 head의 모양이 다르다.
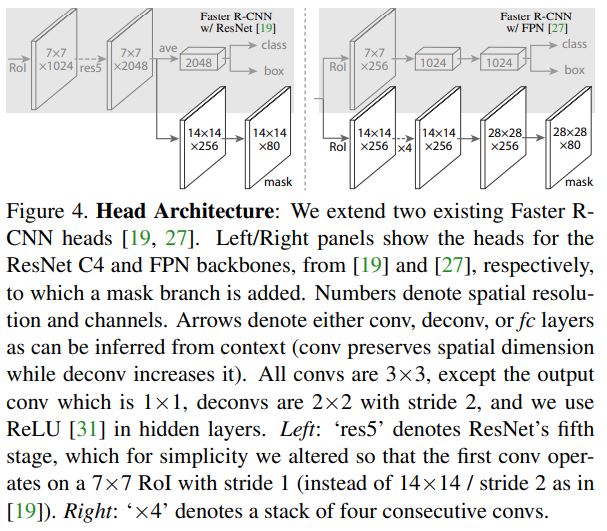
ResNet-C4의 경우 5-th의 res5가 추가되고, 이후에 연산이 진행되고, ResNet-FPN의 경우 이미 res5가 포함되어 있고 더 적은 filter를 사용한다.
3.1 Implementation Details
hyper-parameter의 경우 Fast/Fatser-RCNN에서 사용된 값을 그대로 사용했다. 비록 Detection이었지만 segmentation에서도 robust했다.
Training
Fast R-CNN에서 IoU가 0.5 이상인 RoI만 Positive로 사용되었고 나머지는 negative였다. $L_{mask}$는 positive RoI에 대해서만 정의되었다.
여기 질문이요! The mask target is the intersection between an RoI and its associated ground-truth mask
- 이미지의 사이즈는 짧은 edge를 기준으로 800픽셀
- 1GPU당 2개의 이미지(mini-batch) / 총 8GPU(16 mini-batch가 가장 효율적)
- 160K iterations
- $N$개의 RoI samples, positive:negative = 1:3
- C4 backbone의 경우 $N=64$ / FPN backbone의 경우 $N=512$
- LR 0.02시작 / 120K iter마다 1/10 감소
- weight decay는 0.0001 / momentum 0.9
- ResNetXt의 경우 1GPU당 1개의 이미지 / LR 0.01 시작
- RPN anchors는 5scale + 3ratio
- RPN과 Mask R-CNN은 같은 bacbone 사용, 공유
Inference
Test진행 시 C4 backbone은 300, FPN backbone은 1000의 proposal number을 사용했고, bbox를 예측한 후에 non-maximum suppression을 적용했다. 결과 중 score가 높은 순으로 100개의 detection에 mask branch을 적용했다. 학습할 때 classification과 mask prediction이 병렬로 적용된 방식과는 다르지만 더 빠르고 정확도를 향상시켰다.
4. Experiments: Insatance Segmentation
COCO-dataset을 이용해 다른 SOTA 모델과 Mask-RCNN을 비교했다. 기본적으로 COCO-metrics에 AP(Average Precision) 시리즈를 이용해 평가를 진행했다. 따로 언급이 없는 이상 AP는 mask IoU를 지칭한다. Train Images 80K와 val images 35K를 이용해 학습을 진행했고, 나머지 val image 5k(minival)을 이용해 ablation 실험을 보고했다.
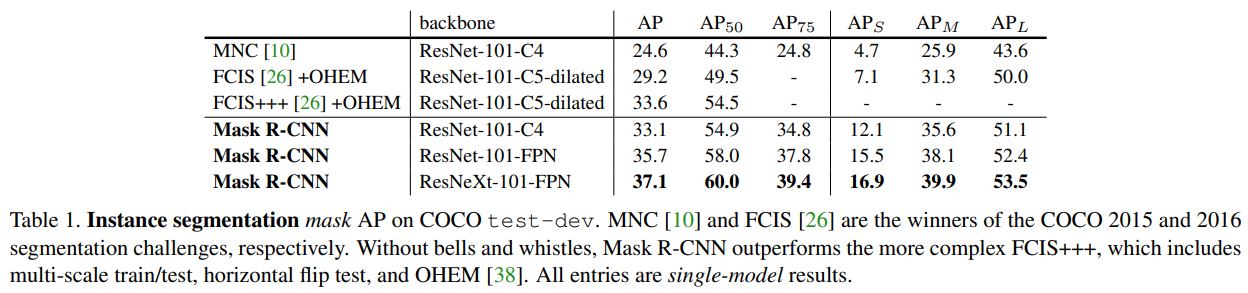
4.1 Main Result
위 표를 통해 이전 SOTA모델과 비교한 결과를 볼 수 있다. 결론은 Mask-RCNN이 모든 영역에서 월등히 좋았다. COCO 2015와 2016의 segmentation 분야 우승작인 MNC와 FCIS를 비교했다.

위 그림은 FCIS와 비교한 결과물이다. FCIS에는 특정 artifacts들이 생겼지만 Mask-RCNN은 생기지 않았다.
4.2 Ablation Experiments
Mask-RCNN을 분석하기 위해 많은 ablation을 진행했다.
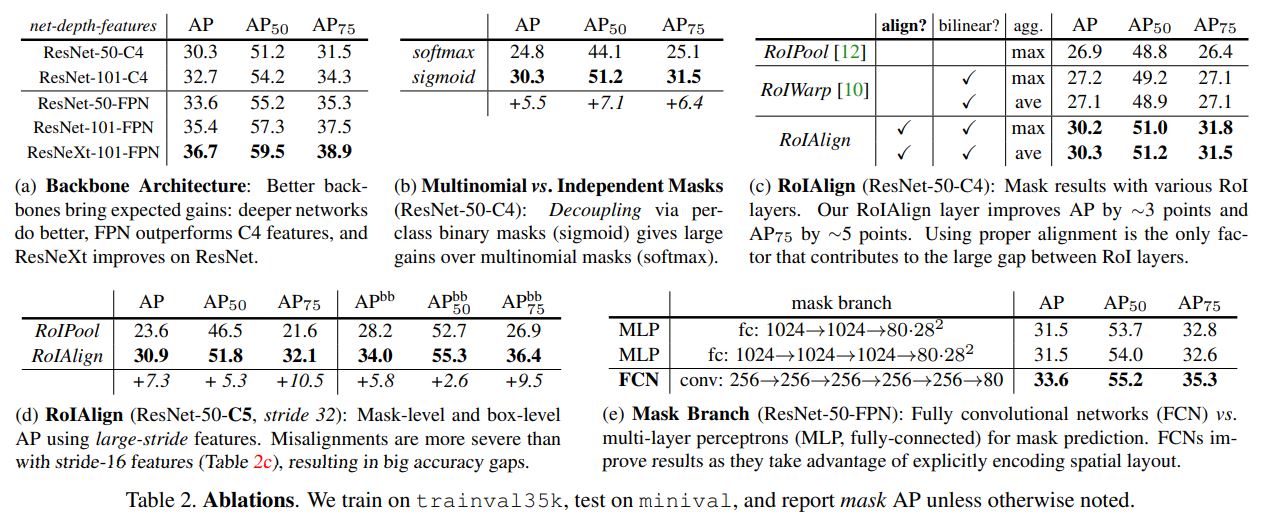
Architecture
위 사진에서 (a) 부분이다. 다양한 사이즈의 ResNet와 FPN/C4 등의 조합을 실험했다. 결과는 deep하고 advanced한 네트워크의 성능이 가장 좋았다.
Multinomial vs Indepent Mask
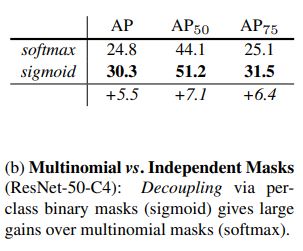
Mask-RCNN은 mask와 class의 prediction이 분리되어있다. 따라서 box branch가 class의 label을 예측하고, mask는 FCNs와 달리 **class간의 경쟁 없이 각 class별로 예측된다. 본 연구에서는 FCN에서 사용한 multinomial한 방식과 비교를 했다. 그 결과 두 테스크를 분리했을 때 더 높은 AP값을 보였다. 즉, softmax보다 sigmoid를 사용했을 때 더 좋은 성능을 보였다. 이를 통해 class와 mask의 예측을 분리하면 mask를 예측할 때 class를 신경쓰지 않아도 되기 때문에 더 쉽게 학습이 된다는 것을 보였다.
Class-Specific vs Class-Agnostic Masks
이것도 질문~ 대체 둘 중 뭐가 맞는거냐. 논문에는 둘 다 같은 말 같음
RoIAlign
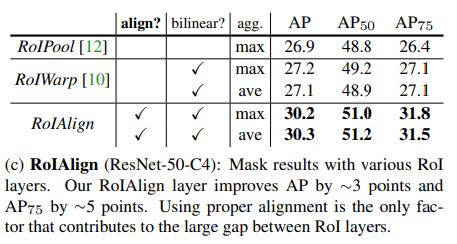
RoIAlign을 RoIPool과 비교를 했는데, 3포인트 정도 더 좋은 성능을 보였다. 또한 RoIAlign은 max또는 avg pool에 둔감하고, 따라서 실험에서는 avgpool을 이용했다. 또한 MNC모델에서 사용한 RoIWrap기법과 비교를 했는데, 상대적으로 성능이 별로 좋지 않았다. 비록 둘 다 bilinear sampling을 방식을 사용했지만, RoIWrap의 경우 여전히 quantization이 되어 alignment를 잃어버리기 때문이다. 따라서 RoIAlign처럼 적절한 alignment를 사용하는 것이 key point이다. 결론은 그 당시에 RoIAlign이 가장 성능이 좋았다.
Mask Branch

Mask를 예측할 때 Fully-connected Layer와 FCN방식을 비교했다. Segmentation는 pixel-to-pixel단위로 예측이 되어야하기 때문에 공간 정보를 최대한 보존하는 FCS 방식의 성능이 더 좋았다.
4.3 Bounding Box Detection Results
COCO dataset에 대해 SOTA의 점수를 가지고 있던 상위 모델과 bounding-box object detection에 대한 성능을 비교했다. 비교를 위해 mask를 예측하는 부분까지 포함해서 전체 Mask-RCNN을 학습시켰고, 비교에는 bbox와 classification의 결과만 사용했다. 결론적으로 ResNet-101-FPN모델을 사용했을 때 과거 SOTA 모델들보다 성능이 좋았고, ResNeXt모델을 사용했을 때 3포인트 더 좋은 성능을 보였다. 또한 mask를 예측하는 부분을 제외하고 RoIAlign을 이용해 detection 부분을 학습했는데, 다른 모델들보다 성능이 좋았다.
마지막으로 bbox의 예 AP와 mask의 예측AP의 격차가 2.7로 매우 작았다. 이것은 segmenation의 테스크가 object detection에 비해 더 어려운데도 불구하고 성능에 차이가 별로 없다는 것을 시사한다.
4.4 Timing
Inference
Faster-RCNN의 4단계 학습 과정에 따라 RPN과 Mask R-CNN이 공유하는 feature를 추출하는 backbone 모델인 ResNet-101-FPN을 학습시켰다.
- Nviida Tesla M40 GPu를 사용 / 1장 당 195ms가 소요됨
- CPU를 사용하여 입력 이미지의 사이즈를 조절 / 1장 당 15ms 소요
- feature를 공유하지 않았을 때와 mask의 AP값 차이가 없음.
- ResNet-101-C4를 사용했을 때 box의 head부분이 깊어서 400ms 정도 나옴
대체 여기서 unshared feature는 무엇을 말하는걸까?
비록 Mask-RCNN은 빠르지만 속도에 최적화하진 않았다. 속도와 정확도는 trade-off관계라 이미지의 사이즈와 proposal number에 의해 영향이 있지만, 이 논문의 주제와 맞지 않아서 다루지 않는다.
Training
Mask-RCNN은 학습이 빠르다. ResNet-50-FPN을 기준으로 COCO trainval35k를 학습했을 때 약 32시간이 소요되었다.(8개의 GPU를 사용했고, 16 mini-batch마다 0.72s가 걸린 셈이다. )ResNet-101-FPN의 경우 44시간이 소요되었다. train dataset을 이용하면 학습시간이 더 짧아지기 때문에 빠른 프로토타입 실험이 가능하다.
Mask R-CNN for Human Pose Esitmation
Mask R-CNN은 Human pose를 estimation할 때도 사용할 수 있다. one-hot mask를 사용했는데, $K$개의 마스크를 예측하고, 각 마스크는 사람의 keypoint가 1개씩 대응된다.
Implementation Details
Keypoint를 위해 segmentation system에 작은 변화를 줬다. 각 instance(사람)에 대해서 $K$개의 keypoints는 각각 one-hot으로 구성된 $m$x$m$의 binary mask으로 표현되고, 이것이 곧 training target이 된다. 학습이 되는 동안 softmax와 cross-entropy loss를 이용해 channel-wise하게 loss를 구한다. Keypoint head(mask head)는 8개의 3x3 512-d filter와 deconv layer, 2xbilinear upscaling layer로 이루어져 있다. 최종 keypoint mask의 결과물은 56x56이다.
- keypoints로 annotated된 COCO trainval35k image으로 학습
- overfit 방지를 위해 [940, 800] randomly sampled
- inference 시 800pixel 고정
- 90K iteration 학습, LR=0.02, 60k와 80k마다 LR 10 감소
- bounding-box NMS 시 threshold는 0.5
Main Results and Ablations
Appendix섹션에서 더 많은 backbone을 다루지만, 우선 ResNet-50-FPN으로 학습한 결과이다. 2016년 COCO 우승자보다 0.9포인트 높은 62.7AP(keypoints)를 달성했다. 또한 bbox, segmentation, keypoints를 동시에 예측하면서 5fps라는 빠른 속도를 달성했다.
지금까지 Mask-RCNN에 대해 알아보았다. 사실 이 뒤에도 더 많은 내용이 있지만, Appendix부분이기 때문에 뭔가 부가적인? 내용들이라고 판단해서 정리하지 않고 읽기만 했다. 단순히 다른 데이터로 실험한 내용, 약간의 테크닉을 이용해 성능을 조금 높인 이야기 등이 있다. 하지만 Mask-RCNN의 핵심은 이미 위에서 전부 언급했기 때문에 적당하다고 생각한다.
읽어주셔서 감사합니다.(댓글과 수정사항은 언제나 환영입니다!)