Fast R-CNN은 2015년 Fast R-CNN이라는 논문을 통해 발표되었다. RCNN시리즈 중 하나인 Fast-RCNN은 RCNN을 발전시킨 모델이다. Object Detection에 사용되는 모델이고, 아키텍처의 변화와 테크닉을 추가해 더욱 발전시켰다.
Abstract
Object Detection을 위한 모델인 Fast Region-based Convolutional Network를 소개했다. 다양한 inovations를 추가해 train,test의 속도와 정확도를 개선했다. VGG16를 backbone으로 R-CNN보다 약 9배 빠르고 test시 213배나 빠르다. SPPnet과 비교하면 각각 3배, 10배 더 빠르고 정확하다. 또한 그 당시 PASCAL VOC 2012데이터셋으로 높은 mAP를 달성했다.
1. Introduction
최근에 classification과 object detection분야가 많이 발전되었다. Object Detection의 경우 classification보다 어려운 문제이기 때문에 더욱 복잡한 모델이 필요하고, 따라서 대부분의 모델이 Multi-stage를 사용하기 때문에 상대적으로 느리다.
Object Detectoin은 정확한 위치값이 필요한데, 값을 계산하는 과정에서 다음과 같은 어려움이 있다.
- 많은 위치좌표 후보군(Proposals)을 모두 처리해야한다.
- Proposals의 좌표를 정확한 좌표로 보정해야한다.
이 논문에서는 SOTA를 달성한 ConvNet기반의 object detector를 소개한다. 즉, 복잡한 구조의 이전 모델과 다르게 Single-stage로 proposals을 분류하고 위치값을 계산하는 모델을 소개한다.
- VGG16를 backbone으로 R-CNN보다 9배 빠름, SPPnet보다 3배 빠름
- 사진 1당 장 0.3초 정도 소요된다.
- 동시에 PASCAL VOC 2012기준 66%의 mAP를 달성(vs R-CNN : 62%)
1.1 R-CNN and SPPnet
Region-based CNN은 Object detectoin분야에서 좋은 정확도를 보이지만, R-CNN의 모델에는 몇 가지 단점이 있었다.
Training is a multi-stage pipeline
- Log loss를 이용해 ConvNet 부분을 Finetune한다.
- finetune한 feature들을 SVMs모델에 학습시킨다.(Softmax classifier 대체)
- Bounding box regressor를 학습시킨다.
이처럼 3단계로 나눠서 학습을 진행한다는 단점이 있다.
Training is expensive in space and time
Disk에 저장한 각각의 object Proposal을 SVM과 bounding box regressor로 학습을 한다. VGG16사용했을 때 VOC2007 데이터셋 5k를 하는데 2.5GPU-day정도 소요되었다. 또한 많은 저장공간을 차지한다.
Object Detection is slow
test-time 시 test이미지에서 생성된 각각의 object proposal마다 feature를 추출하기 때문에 매우 오래 걸린다.(47s/image on GPU)
feature를 추출할 때 계산이 proposal마다 공유가 되지 않아서 매우 오래 걸린다. SPPnets의 경우 RCNN의 시간문제를 해결하기 위해 1개의 Image전체로부터 feature vector를 추출하고 분류한다. Proposal이 생성되면 부분 maxpooling을 이용해 모두 동일한 size로 변환하고, Spatial pyramid pooling을 실시한다. test시 100배, train시 3배정도 빨라졌다.
하지만 SPPnet도 단점이 있다. R-CNN와 동일하게 학습 시 log loss, SVMs, bounding box regressor 학습 등의 multi-stage방식을 이용하기 때문에 복잡하다. 또한 RCNN과는 다르게 finetune진행 시 SPP 이전의 CNN layer들을 업데이트 하지 못했다.
1.2 Contributions
논문에서는 R-CNN와 SPPnet의 단점을 고치고 속도와 정확도를 향상시키는 Fast R-CNN고안했다. 장점은 다음과 같다.
- R-CNN, SPPnet보다 높은 mAP
- Single-stage로 학습하고 multi-task loss를 사용
- 모든 layer 업데이트 가능
- feature를 따로 저장할 필요 없음
2. Fast R-CNN architecture and training
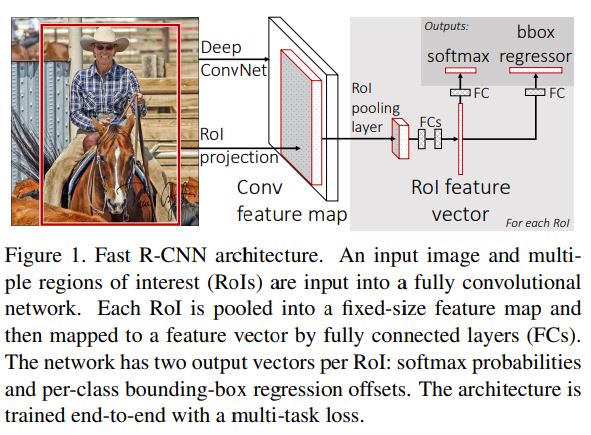
Fast R-CNN의 과정은 다음과 같다.
- object proposals이 포함되어 있는 전체 이미지를 모델의 Input으로 사용한다.
- 이미지 전체를 Conv와 maxpooling을 적용시켜 Conv feature map을 만든다.
- RoI Pooling layer를 이용해 feature map을 동일한 size의 vector로 변환한다.
- Vector가 Fully-connected layer에 의해 연산이 되고 2가지 종류의 output을 생성한다.
- 하나는 (K Classes)+1(배경)에 대해 분류를 진행하고, 다른 한쪽은 특정 K에 대해 bounding box를 보정한다.
2.1 The RoI Pooling Layer
RoI Pooling Layer는 Region of interest(RoI, feature map에 proposals를 projection해놓은 상태)를 모두 동일한 사이즈(HxW)의 작은 feature map으로 변환한다. 이 논문에서 RoI는 다음과 같이 표현된다.
RoI Max Pooling은 다음과 같이 작동한다.
- $h$x$w$ 사이즈의 RoI를 $W$x$H$로 나눈다.(가로,세로 길이는 각각 $h/H$, $w/W$이 된다.)
- 각 RoI에 대해 독립적으로 Max Pooling이 적용된다.
- 크기가 다른 RoI에 대해서 모두 동일한 size의 Output이 출력된다.
SPPnet에서 사용된 Spatial Pyramid Pooling layer의 간단한 버젼이다.
2.2 Initializing from pre-trained networks
논문에서는 ImageNet 데이터로 사전학습 된 3가지 모델을 사용해서 실험을 진행했다. 해당 모델이 Fast R-CNN을 초기화했을 때 3가지 변환이 발생한다.
- 모델의 마지막 Maxpooling layer는 RoI Pooling layer로 대체된다. 그리고 첫 FC layer와 연결할 수 있도록 output의 size를 수정한다.(VGG16일 때 $H=W=7$)
- 모델의 마지막 FC Layer와 Softmax는 앞에서 다뤘던 2개의 Layer로 찢어진다. K+1 class를 분류하는 layer와 bounding box를 regression하는 layer로 바꾼다.
- 2개의 data를 input으로 받는데, 하나는 Image의 list, 또다르 하나는 각 Image별 RoI이다.
2.3 Fine-tuning for detection
역전파를 이용해 네트워크의 모든 가중치를 학습하는 것은 Fast RCNN의 능력이다. 먼저 SPPnet의 spaital pyramid pooling layer 밑으로 학습이 불가능한지에 대해 설명하면 다음과 같다.(해당 문단을 다 읽고 이해한 내용을 바탕으로 작성했다.)
가장 중요한 이유는 R-CNN과 SPPnet의 경우 training에 참여하는 sample들은 서로 다른 image로부터 추출된 RoI이다. 이런 RoI들은 매우 큰 사이즈를 가지고 있을 수 있고, 심지어 input 이미지의 전체를 사용해야할 경우도 있다. 이 논문에서는 training을 하는 동안 feature를 공유하는 방식을 제안했다. Fast R-CNN을 학습할 때 SGD mini-batch방식을 사용했다. 먼저 N개의 image에서 R/N개의 RoI를 Sampling한다. (여기서 중요한 점은 같은 이미지로부터 생성된 RoIs들은 forward와 backwrad 시 연산과 메모리를 공유한다는 것이다.) N을 작게하면 mini-batch의 연산량도 작아진다. 예를 들어 $N=2$이고 $R=128$으로 학습을 하면 ‘128개의 다른 이미지로부터 각 1개씩 RoI를 추출한 후에 학습’(마치 R-CNN이나 SPPnet이 하는 것처럼)했을때보다 약 64배 빠르다.
더 나아가 Fast R-CNN은 Softmax classifier, SVMs, Regressor를 따로 학습하는 이전 모델들과 다르게 softmax classifier와 regressor를 하나의 stage로 최적화할 수 있는 구조를 가지고 있다.
다음 내용에 효율적인 학습을 가능하게 하는 요소들을 나열했다.
Multi-task loss
Fast R-CNN은 두 가지 Output Layer를 가지고 있다. 하나는 Softmax를 이용해 $K+1$개의 class를 예측하는 부분($p=(p_0, …, p_K$))이고, 또다른 하나는 각 k class별로 적용해주는 bounding box regression($t^k = (t^k_x,t^k_y,t^k_w,t^k_h$))이다. bbox regression 시 object Proposal에 대해 scale-invariant변환과 log-space height/width변환을 적용한다.
각 RoI들은 class $u$와 bbox regression target $v$로 라벨링되어있다. 우리는 각 RoI에 대해 classification과 bbox regression을 합친 multi-task loss $L$를 사용한다.
- $L_{cs}(p,u)$: 정답 class인 $u$에 대한 log loss($-\log{p_u}$)을 말한다.
- $L_{loc}$: class $u$에 대한 정답 bbox regression target($v = (v_x,v_y,v_w,v_h))$과 예측 bbox($t^u = (v^u,v^u,v^u,v^u))$)와의 loss이다.
위 식에서 $[u \geq 1]$위 표시는 만약 $u$가 1보다 크면 1이고 나머지는 0이라는 뜻이다. $u$는 클래스의 label인데, 만약 RoI가 background($u=0$)이면 ground-thruth가 없기 때문에 $u=0$일 때 $L_{loc}$를 0으로 만들어주기 위해 사용하는 관습이다.
$[u \geq 1]$와 같은 표현을 Iverson bracket이라고 한다.
Bounding box regression은 다음과 같은 Loss를 사용한다.
Robust $L_1$ loss는 R-CNN과 SPPnet에 사용하는 $L_2$ loss에 비해 이상치에 민감하다. 만약 regression의 target에 제한이 없다면, $L_2$ loss의 경우 학습률을 매우 세심하게 조절해야한다.
하이퍼파라미터인 $\lambda$는 두 loss의 발란스를 맞추는 역항를 한다.
- 모든 실험에 대해 $\lambda = 1$로 설정
- Ground-thruth인 regression target $v$은 평균이0이고 분산이1인 값으로 정규화한다.
Localization과 classification을 서로 다른 두 network로 설계한 OverFeat, R-CNN, SPPnet등과 같은 모델을 stage-wise training라고 칭한다.
Mini-batch sampling
- Fine-tuning 시 SGD mini-batch방식을 이용하는데 $N=2$ images를 사용하고, 이미지는 uniformly random하게 선택한다.
- $R=128$로 설정하여 각 이미지당 64개의 RoI를 생성한다.
- RCNN과 동일하게 RoIs의 25%는 ground-thruth와의 IOU값이 0.5이상($u \geq 1$)인 것을 사용한다.
- 나머지 RoIs 중 IOU값이 $[0.1, 0.5)$인 RoIs는 background($u=1$)로 간주한다.
Back-propagation through RoI pooling layesr
이 부분은 아무리 봐도 모르겠다. 너무 수학적인 내용이라 이해가 안 간다. 인터넷을 찾아봐도 이것에 대해 얘기하는 사람이 별로 없다….
SGD hyper-parameters
Classification과 bbox regression에 사용하는 FC layer는 평균이 0이고, 표준편차가 각각 0.01, 0.001로 하는 정규분포로, bias는 0으로 초기화한다. 글로벌 learning rate는 0.001로 설정한다. VOC07 또는 VOC12를 학습할 때는 먼저 30K mini-batch iterations를 이용했고, 이후 10k는 LR을 0.0001낮췄다. momentum은 0.9, decay는 0.0005로 설정했다.
2.4 Scale Invariance
Scale-Invariance한 object detection모델을 만들기 위해 2가지 방법을 실험했다. Input 이미지를 특정 사이즈로 고정시킨 후 train과 test를 하는 ‘Brute-force’방식과 image pyramid방식을 이용하여 대략적인 Scale-invariance를 부여해 학습을 시키는 ‘Multi-scale approach’가 있다. 하지만 GPU메모리 문제로 대부분의 경우 ‘Brute-force’방식을 사용했다.
3. Fast R-CNN detection
Fast R-CNN은 이미지 또는 이미지 list와 R개의 object proposals을 input으로 받는다. Test시 R은 보통 2000으로 설정하지만, 더 큰 값도 실험했다. 각 RoIs에 대해 class와 bbox를 예측한다. Class를 예측할 때는 각 RoIs의 class에 대한 확률값(confidence score)을 부여한다. 마지막으로 확률값을 기준으로 RCNN와 동일한 방법을 이용해 NMS을 적용한다.
3.1 Truncated SVD for faster detection
Classification을 할 때는 Conv연산량이 FC연산보다 더 많다. 하지만 Detection에서는 모든 RoI에 대해 FC를 적용해야하기 때문에 FC연산이 더 많다. 따라서 Truncated SVD를 이용해 FC layer에서의 연산을 가속화했다.
FC Layer의 가중치($W$)를 $u$ X $v$형태로 factorized하면 다음과 같다.
SVD(특이값분해)를 통해 $W$를 다른 행렬로 분해할 수 있다. SVD는 기존 파라미터의 개수였던 $uv$를 $t(u+v)$로 줄이는 효과가 있다. $t$는 사이즈가 $t$x$t$인 대각행렬이다. $\Sigma_{t}$의 사이즈($t$)가 $\min(u,v)$보다 작을 때 더욱 효과적이다. 이처럼 네트워크를 압축하기 위해 하나의 FC Layer를 두 개의 FC Layer로 대체하면 파라미터의 수를 줄일 수 있고, 결과적으로 속도가 빨라진다.
4. Main Results
논문에서는 3가지 결과에 대해 언급했다.
- VOC2007, 2010, 2012에서 SOTA달성
- R-CNN, SPPnet보다 빠른 training 및 testing
- VGG16을 fine-tuning하면서 mAP 향상
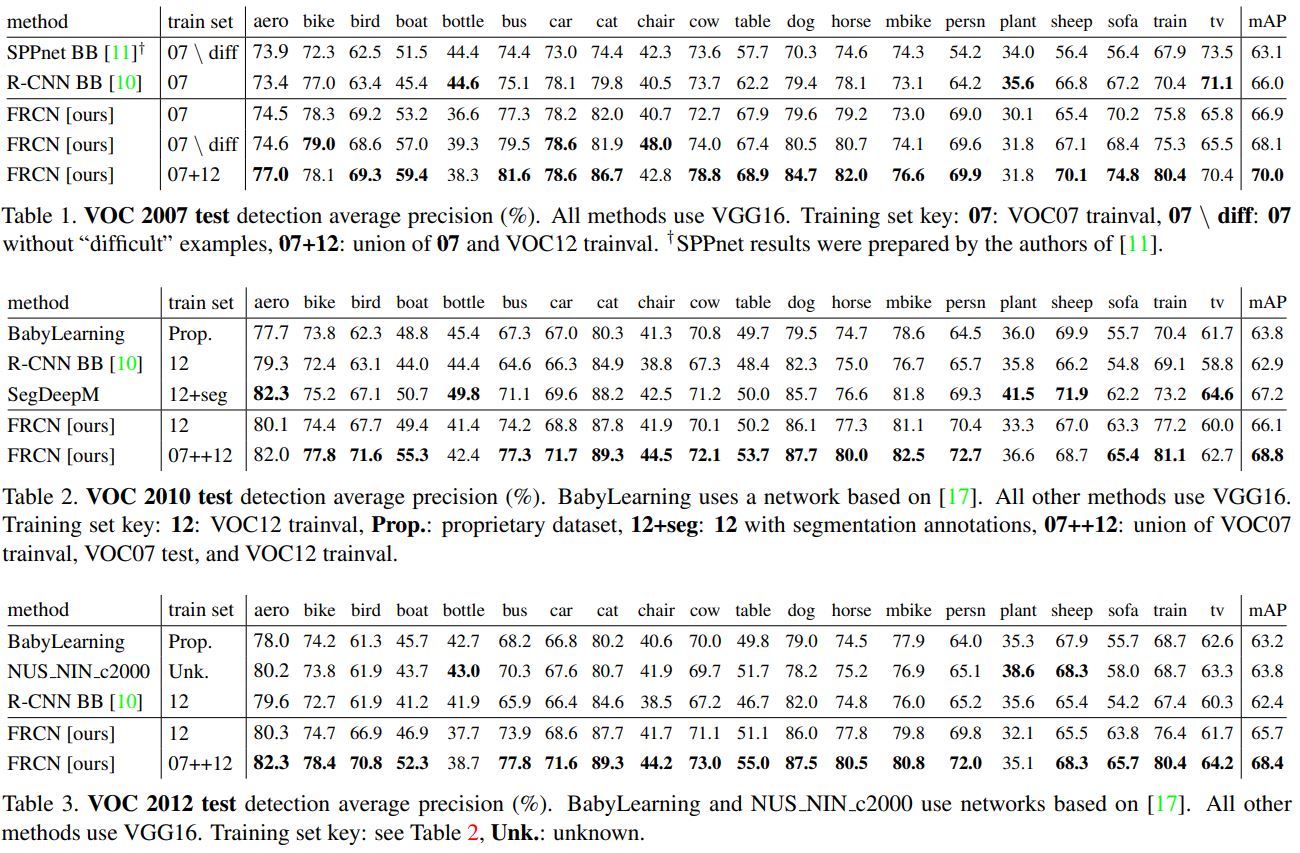
4.1 Experimental setup
실험에는 3가지 pre-trained된 ImageNet모델을 사용했다. 첫 번째는 R-CNN에서 사용한 AlexNet(S)이다. 두 번째는 VGG_CNN_M_1024(M)이다. 첫 번째와 비슷하지만 더 wider한 모델이다. 마지막 모델은 very deep VGG16(L)이다. 모든 실험에서는 한 가지 scale만 사용했다.(s=600)
4.2 VOC 2010 and 2012 results
NUS_NIN_c2000과 BabyLearning methods와 비교를 진행했다. VOC2012에서는 Fast R-CNN이 mAP 65.7%로 가장 좋은 성능을 보였고, 다른 모델들보다 빨랐다. 하지만 VOC2010에서는 SegDeepM이 더 높은 성능을 보였다. 이 모델은 R-CNN모델을 boost하기 위해 Markov random field를 사용했다.
4.3 VOC2007 result
R-CNN, SPPnet, Fast R-CNN을 비교했다. 모두 같은 pre-trained VGG16로 시작했다. SPPnet은 5개의 scale를 사용했지만 1가지 scale만 사용한 Fast RCNN이 더 좋은 성능을 보였다. 한 가지 단점은 SPPnet의 경우 ‘difficult’라고 칭하는 example로 학습을 하지 않았다는 점이다. 이 example은 Fast RCNN의 성능을 향상시켰다.
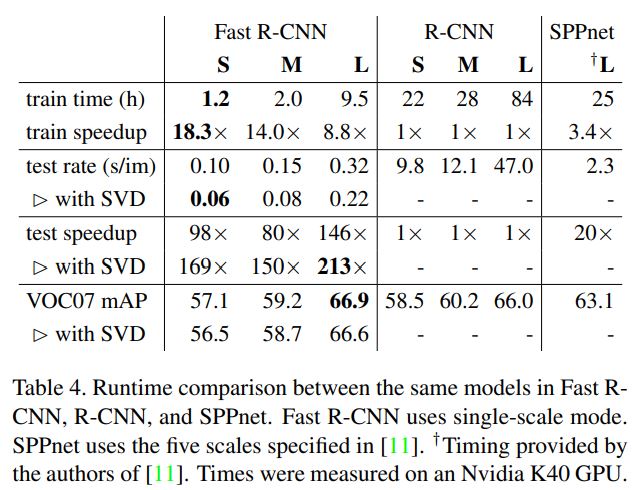
4.4 Training and Testing time
Training과 Testing의 시간을 비교했다. 글로 길게 적어놨는데 그냥 표를 그대로 해석한 것 뿐이다.
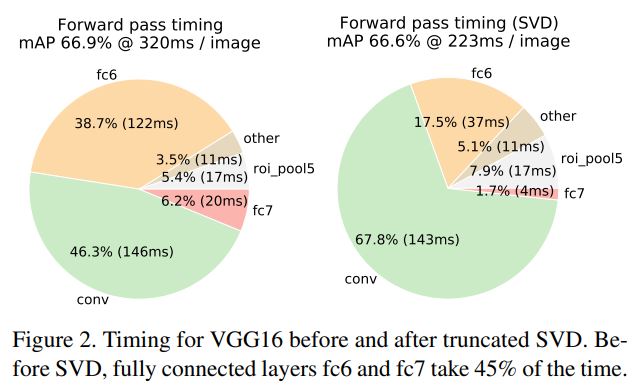
Truncated SVD
Truncated SVD는 작은 mAP 감소로 detection소요시간을 약 30%정도 줄일 수 있다. 아래 사진은 각 단계별로 소요되는 시간이고, SVD를 사용했을 때 줄어든 시간 차이를 나타냈다.
4.5 Which layers to fine-tune?
SPPnet에서는 fine-tuning을 FC layer에 적용했을 때 좋은 성능을 보였다는 결과를 냈다. 하지만 이 논문에서는 SPPnet의 결과가 모든 네트워크에 동일하게 적용되지 않는다고 생각했다. 따라서 VGG16의 각 layer별로 fine-tuning의 중요성을 파악하기 위해 Fast RCNN학습 시 각 layer별로 freeze를 실시했다.

SPPnet과 다르게 Conv Layer도 fine-tune했을 때 성능이 향상됐다. 그렇다면 Conv Layer를 전부 fine-tune해야 좋은 걸까?
그건 아니라고 한다. 작은 백본 네트워크 인 경우에는 conv1 layer는 아무 영향도 주지 않는다. 왜냐하면 generic하고 task independent하기 때문이다. 즉, conv1 layer는 어떤 모델이든 다 동일한 역할을 한다는 것이다.
- 결과적으로 VGG16를 사용하면 conv3_1 layer부터 업데이트를 해야한다.
- conv2_1부터 하면 training 시간이 증가한다.(9.5 hours to 12.5 hours)
- conv1_1부터 하면 GPU의 메모리가 초과된다.
- conv2_1부터 학습한 결과와는 0.3point 밖에 차이가 안 난다.
- 이 논문에서 언급되는 Fast RCNN은 모두 conv3_1부터 fine-tune을 했다.
- 그리고 S와 M 모델을 사용한 경우는 conv2 layer부터 fine-tune을 했다.
5. Design evalutation
디자인 측면에서 Fast RCNN과 SPPnet, RCNN과의 차이를 알기 위해 실험을 진행했다. PASCAL2007를 이용했다.
5.1 Does multi-task training help?
Multi-task training은 파이프라인을 만들어 개별적으로 학습을 시켜야하는 번거로움을 없애준다. 과연 multi-task training은 Fast RCNN의 detection 성능을 향상시킬까?

결과적으로 Multi-task는 성능을 향상시켰다.
5.2 Scale Invariance: to brute force of finess?
object detection에 대한 scale-invariance의 영향을 알아보기 위해 두 2가지를 비교했다. brute-force learning(single scale)과 image pyramids(multi-state). 이미지의 짧은 모서리를 s로 설정했다.
single scale의 경우 600으로 통일했다. 하지만 PASCAL의 경우 평균 사이즈가 384x473이기 때문에 single scale의 경우 upsample을 실시했다. Multi-sacle은 총 5개의 사이즈를 사용했다.(480, 576, 688, 864, 1200)
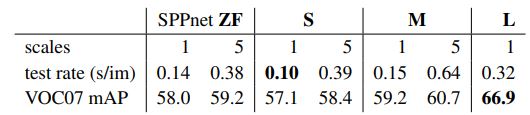
결과적으로 single-scale과 multi-scale의 차이는 미미했다. 하지만 multi-scale의 경우 연산량이 많아진다는 단점이 있다. 심지어 VGG16모델, 즉 가장 큰 모델의 경우 single-scale방식이 약간의 성능향상을 보였다. 속도와 정확도의 trade-off관계에 있어서 single-scale이 효율이 가장 좋기 때문에 모든 실험에 대해 s=600으로 통일했다.
5.3 Do we nedd more training data?
좋은 detector는 training data가 더 많아지면 성능이 더 좋아진다. DPM의 경우 몇 백개의 데이터를 추가했을 때 mAP가 증가했다. VOC2007과 VOC2012를 합친 결과 약간의 성능향상을 보였다. VOC10과 VOC12에 대해서도 실험을 진행했다. 그 결과 성능이 약 2%정도 향상했다.
5.4 Do SVMs outperform softmax?
Softmax와 SVMs의 차이를 비교하기 위해 실험을 진행했다.
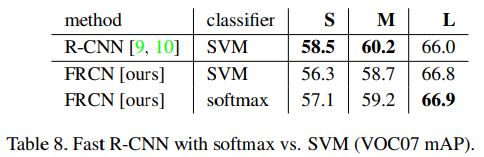
그 결과 VGG16에 대해서는 아주 작은 차이를 보였다. 하지만 one-shot training이 multi-stage보다 월등히 효율적이기 때문에 Softmax를 사용했다.
5.5 Are more proposals always better?
Detector에는 두 가지 버젼이 있다. Selective search와 같이 sparse set of object proposal을 사용하는 것과 DPM과 같이 dense set(각 픽셀마다 전부 추출)을 사용하는 버젼이 있다. Sparse proposals를 분류하는 것은 마치 cascade와 같다. proposal 메카니즘이 몇 개의 후보를 미리 삭제하기 때문이다. 이러한 cascade 방식이 DPM detection의 성능을 향상시킨다. 또한 cascade방식이 Fast RCNN을 향상시킨다는 evidence도 발견했다.
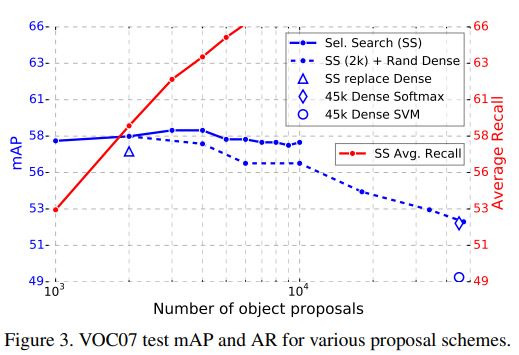
Proposal이 증가하면 mAP도 조금 증가하지만 어느 시점부터는 감사한다. 즉 무조건 proposal이 많다고 좋은 것은 아니다. 심지어 성능에도 악영향을 미친다.
하지만 SOTA에서 object Detectoin의 성능을 평가할 때 Average Recall(AR, 빨간선)을 사용한다. RCNN을 사용할 때 proposal이 일정하면 AR은 mAP와 상관관계가 있다. 하지만 Proposal이 많아져서 AR이 높아지면, 어느 시점부터는 mAP와의 상관관계가 없어진다. 그 이유는 당연히 후보가 많아지면 recall이 많아질 수밖에 없기 때문이다. 결과적으로는 selective search가 가장 좋다.
6. Conclusion
Fast RCNN은 RCNN과 SPPnet과 비교해서 빠르고 덜 복잡한 모델이다. SOTA를 달성했고, 여러 방면에서 Fast RCNN이 더 좋은 성능을 보였다. 물론 Proposal의 증가는 성능향상에 도움을 주었지만, 연산시간 대비 너무 비효율적이다. 이후 기술이 발전하면 Dense proposal을 사용해도 성능이 향상되는 날이 올 지도 모른다.
지금까지 Fast RCNN의 논문을 리뷰했다. RCNN보다 약간의 성능이 추가된 느낌이라 성능이 좋아졋지만 아직 해결해야할 부분이 많은 것 같다. 특히 Proposal을 생성하는 부분이 여젼히 CPU를 사용하는 Selective Search를 이용하고 있기 때문에 지금의 시점으로는 매우 이해가 안 간다. 그래도 지금의 기술들이 발전할 수 있었던 것은 이러한 연구들이 있었기 때문에 가능한 것이라고 생각한다. 따라서 과거 연구들을 보며 insights를 얻는 것은 매우 중요한 것 같다.
Fast RCNN의 과정을 정리하면 다음과 같다.
- input은 2개의 data 넣는다. (list of image와 proposals)
- Multi-loss를 사용한다.
- pre-trained된 VGG를 사용하고 2개의 output layer구조를 추가한 후에 fine-tune을 진행한다.
- 이때 SGD mini-batch를 사용하는데, N=2로, RoI=128로 설정 / 64RoIs for each images
- Sampling 시 RoIs중 25%는 IOU 0.5넘는거, 나머지 중 $[0.1, 0.5)$은 background 사용