RCNN은 2014년 Rich feature hierarchies for accurate object detection and semantic segmentation라는 논문을 통해 발표되었다. 딥러닝을 이용한 초기 모델이기 때문에 현재 시점에서 모델의 구조를 본다면 굉장히 비효율적인 부분이 많이 존재한다. 하지만 그 당시에는 Object Detection 분야에 큰 변화를 불러온 모델이다. 이미지로부터 특징을 추출하는 여러 Descriptor(HOG, SIFT 등)가 사용되었는던 과거와 다르게 딥러닝(CNN)을 이용해 Object Detection문제를 해결하였다.
1. Introduction
물체를 인식하는데 가장 핵심이 되는 부분은 Image Feature를 표현하는 부분이다. 과거에는 SHIFT나 HOG와 같이 low-level feature들이 사용되었는데, 이러한 방법들은 Bottle Nect 현상을 야기했다. 한 가지 feature만 사용하지 않고 여러 feature를 조합했을 때 PASCAL Visual Object Classes(VOC Challenge)의 benchmark 데이터를 기준으로 mAP값을 약 10%정도 향상시켰다. 하지만 아쉽게도 이러한 방법은 시간이 갈수록 나아지지 않았다.
그래서 연구자들은 Deep Learning기술에 관심을 가지기 시작했고, 실제로 AlexNet이 Classification 분야의 대표적인 BenchMark인 ImageNet 대회(ILSVRC)에서 놀라운 성과를 보이면서 딥러닝 열풍이 시작되었다. 그러면서 이러한 방식이 Object Detection에서도 사용될 수 있지 않을까라는 기대감을 품고 연구를 진행했다.
CNN구조는 과거부터 Sliding Window Detector로 사용되어왔다. 즉, Image의 처음부터 끝까지 Slide를 하면서 탐색을 진행했다. 하지만 이러한 방식은 매우 비효율적이었고, 높은 Computational cost를 야기했다. 대신에, “recognition using regions방식을 사용하게 되었다. 실제로 매우 효율적이었고 Slide Window방법보다 계산량도 약 2배정도 작았다.
2. Object Detection
RCNN은 크게 3가지의 모듈로 나눠져있다.
- category-independent region proposals
- large convolutional neural network
- set of
- class-specific linear SVMs
2-1. Module design
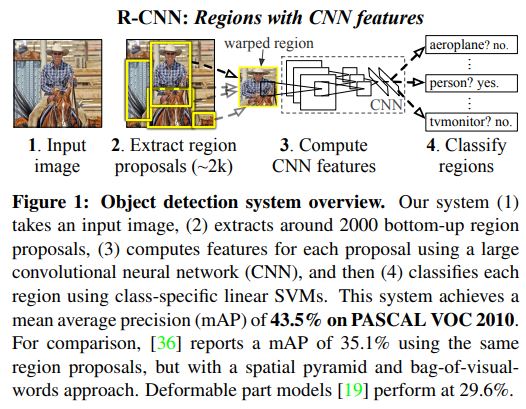
Region Proposal
이미지 내에서 Object의 후보군을 추출하는 부분이다. Objectness, Selective search, category-independent object proposals, constrained parametric min-cuts (CPMC) 등 다양한 기술이 있지만 RCNN의 경우 Selective Search방법을 채택했다.
Feature extraction
CNN을 이용해 Region Proposal부터 약 4096-dimension의 feature를 추출했다. 고정된 이미지 사이즈인 224x224를 사용했고 5개의 CNN Layer와 2개의 Fully-connected layer를 사용했다. Region Proposal에서 추출된 다양한 크기의 이미지를 모두 같은 사이즈인 224x22x로 warp했다.
2-2. Inference
Selective search(fast mode)로부터 약 2000개의 proposal를 추출하고 CNN과 Fully-connected layer를 이용해 feature extraction을 진행한다. 이후에는 각 class에 대해 추출된 feature map을 SVM 모델을 이용해 score를 산출했다.
Run-time analysis
Run-Time의 속도를 증가시키는 요인으로는 약 2가지가 있다. 첫 번째는 모든 class에 대해 같은 CNN parameters를 사용했다는 것이고, 두 번째는 CNN으로부터 계산된 feature vector가 ‘spatial pyramids with bag-ofvisual-word encodings’와 같은 방법들보다 더 낮은 차원의 vector를 가진다는 것이다. 공유한 결과 GPU에서는 13s/image의 속력이, CPU에서는 53s/image정도의 처리속도가 나온다.
Class별로 Feature와 SVM weights, non-maximum suppression 사이에는 행렬곱이 이루어지는데, feature matrix의 경우 2000 x 4096의 크기를 갖고, SVM weight의 경우 4096 x N의 크기를 가진다. N의 경우 class의 개수이다. class의 개수가 많아져도(100k classes) 행렬곱은 굉장히 빠르게 이루어진다.
2-3. Training
ILSVRC 2012 데이터셋을 이용해 CNN 부분을 Pre-training했다. 학습간에는 3번에 걸쳐 learning rate를 1/10만큼 감소시켰다. AlexNet와 error rate이 2.2%정도 차이가 났다. 이후에는 Detection에 맞도록 fine-tunning작업을 실시했다. PASCAL 데이터셋로부터 warped한 region proposal을 학습시켰다. SGD방법을 사용했고 learning rate는 0.01값을 사용했다. IOU가 0.5보다 큰 region proposal만 Positive를 사용했고 나머지는 Negative로 설정했다.
Object category classifiers
정답 class와 비슷한 region image의 경우 해당 class로 설정하면 되지만, 만약 부분적으로 겹쳐있는 region image의 경우 IOU값을 이용해 0.3값을 기준으로 positive와 negative를 분류했다. 0.3이라는 값은 grid search{0 ~ 0.5} 실험을 통해 나왔는데, 0.5로 하면 mAP가 5만큼, 0으로하면 mAP가 4만큼 감소했다.
training label로 설정이 되었으면 class별로 one linear SVM을 optimize했다. 각각의 class에 대해 수렴이 빠르게 진행되는 Standard hard negative mining 기법을 이용했다.
2-4. Results on PASCAL VOC 2010-12
UVA와의 비교가 가장 인상적이다. 본 연구와 같은 Region proposal 알고리즘을 사용했기 때문이다. 하지만 UVA의 경우 classify를 하는 과정에서 four-level spatial pyramid와 SIFT 등을 사용했다. Multi-feature 방식을 사용한 UVA보다 non-linear kernel SVM를 사용한 본 연구가 더 정확하고 빠르다.
3. Visualization, ablation, and modes of error
3-1. Visualizing learned features
각각의 layer들이 어떻게, 그리고 무엇을 학습했는지에 대해 non-parametric한 방법으로 display했다. 모든 network를 사용하지 않고 중간 layer까지를 network로 가정을 한 후에 결과를 시각화했다. 예를 들어 pooling layer 부분인 pool$_5$ 까지를 network로 설정했고, 뒤에 오는 layer들은 사용하지 않았다. 이런 방식으로 다양한 실험을 한 결과 다음과 같다.
3-2. Ablation studies
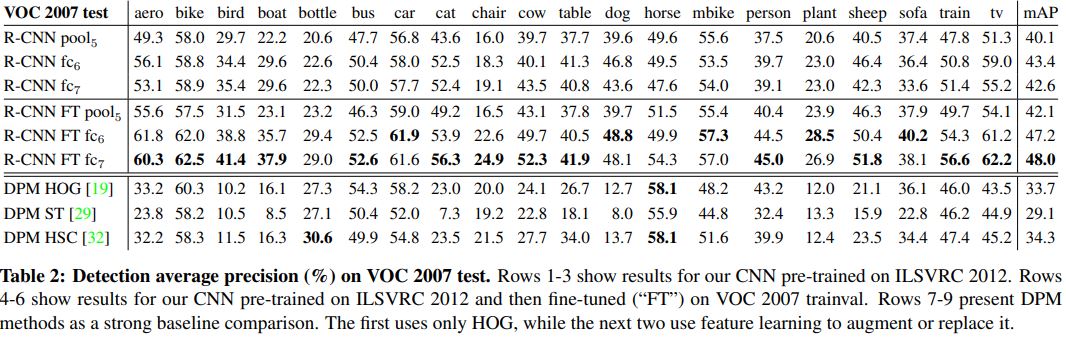
Performance layer-by-layer, without fine-tunning.
각 layer들의 영향력을 알아보기 위해 다양한 실험을 진행했다. 먼저 fine-tune을 진행하지 않은 상태로 실험을 했는데(표 1~3 row) fc$_7$과 fc$_6$의 차이가 별로 없었다. Parameters의 수는 29%나 줄었는데 비해 정확도 감소가 없었다. 심지어 두 레이어 모두 없앤 상태가 더 좋은 경우도 있는데, 이건 단지 6%의 parameter만 사용했다.
Image의 object를 representation하는 것은 CNN Layer가 좌지우지한다.는 결론을 낼 수 있다.
Performance layer-by-layer, with fine-tuning
Fine-tunning을 적용하여 실험을 진행했다. 적용을 안 했을때보다 확실히 성능은 올라갔다. 그리고 pool$_5$에 비해 fc$_7$과 fc$_6$에서 비교적 많이 boost 되었다.
ImageNet으로부터 학습한 Feature는 PASCAL에 매우 중요한 역할을 한다는 사실을 알 수 있고, feature들이 fc$_6$에서 어떻게 optimally하게 combine되냐에 따라 성능이 달라진다.
Comparison to recent feature learning methods
과거에 사용한 대표적인 3가지 DPM방식(HOG, ST, HSC)와 비교를 진행했다. 결과는 위 사진에서 볼 수 있다.(표 7~9 row) 우선 RCNN이 가장 뛰어난 성능을 보였고, 특히 HOG feature만 사용한 DPM 최신 버젼과 비교했을 때 무려 14point나 차이가 났다. RCNN이 짱이다.
3-3. Detection error analysis
4. Semantic segmentation
이 부분은 Object Detection과 조금 벗어난 주제이기 때문에 다음에 다루는걸로~
5. Discussion
본 연구의 방법의 성능이 좋았던 이유는 많은 양의 데이터셋을 사용했기 때문이다. 그럼 다른 방법들은 왜 많은 데이터셋을 사용하지 않을까? 이유 중 하나는 다른 domain 데이터셋(다른 문제를 해결하기 위해 label된 데이터셋)을 이용하는 건 별로 도움이 안 되기 때문이고, 또다른 이유는 대부분 과거의 방법들은 방대한 데이터셋을 수용할 수 있는 parameter가 없기 때문이다.
하지만 RCNN의 경우 방대한 데이터셋을 충분히 수용할 수 있고 또 데이터가 많을수록 더욱 효과적이다.
RCNN 논문을 리뷰해보았다. 하지만 논문만 봐서는 하나하나 기능들이 어떻게 구현되고 실행되는지 잘 감이 잡히지 않는다. RCNN을 리뷰해놓은 다른 블로그들을 보면 세세한 정보까지 알고 있던데, 논문에는 그런 내용들이 전혀 나오지 않는데 어떻게 아는건지 참 심기하다. 아마도 코드를 보거나 그 분들도 다른 참고자료를 이용한 것 같은데, 나도 깊은 이해를 위해서는 다양한 자료를 참고해야할 것 같다.