이번 포스터에서는 기계학습을 하다보면 자주 겪는 과적합(Overfitting)에 다뤄보도록 하겠다.
과적합(Overfitting) 이란?
이름에서도 알 수 있듯이 과적합(Overfitting) 이란 ‘학습데이터에 과하게 학습이 되었다’는 뜻이다. 기계학습을 통해 학습을 하다보면 학습데이터에 대한 손실함수가 감소하는 방향으로 모델이 학습이 되지만, 실제데이터 에 대한 오차가 감소하지 않거나 학습 데이터에 대한 오차가 어느 지점부터 증가하는 순간을 말한다. 즉, Training Datasets에 대해서만 너무 적합한 모델이 되어버린 상태이다.
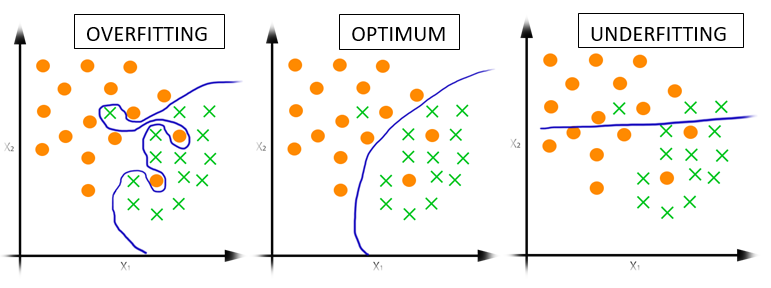
일반화(Generalization)
다음과 같이 입력값(X)에 대해 출력값(Y)을 예측하는 모델이 있다고 하자.
모델이 ‘학습’한다는 것의 의미는 입력값(X)에 대해 출력값(Y)을 예측하는 $f()$를 찾는 것이다. 풀고자 하는 문제(Classification, Object Detection, etc)에 대해 적절한 데이터(X)을 사용해서 원하는 예측값(Y)을 출력하는 $f()$를 구해야하는데, 이때 가장 중요한 것은 실제 데이터(test Dataset)에 대해서 잘 작동해야 한다는 것이다.
다시 말하면 모델을 ‘학습 데이터’를 이용해 학습을 하지만, 실제로 모델이 예측해야 하는 건 학습에 참여하지 않았던 ‘실제 데이터’인 것이다. 사실 ‘학습 데이터’는 ‘실제 데이터’의 일부를 나타내기 때문에 결국 ‘실제 데이터’에 대해서 예측을 하지 못 하면 아무 쓸모없는 모델이 된다.
우리가 수집한 데이터는 실제 의 일부이고 불완전하고 노이즈가 많기 때문에 New Data에 대해 일반화(Generalization)가 될 필요가 있다.
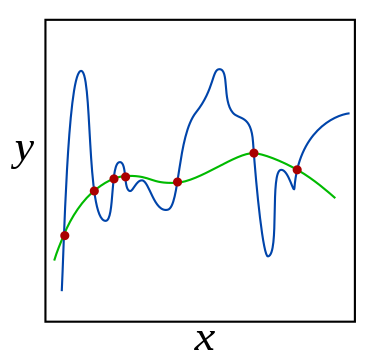
과적합이 발생하는 이유
과적합이 발생하는 이유는 매우 다양하지만, 대표적으로 다음과 같다.
- 학습 데이터에 노이즈가 많은 경우
- 모델이 너무 복잡할 때(=파라미터의 수가 많을 때)
- 학습하는 데이터가 매우 부족할 때
모델의 복잡성(Parameter의 수)과 과적합의 관계
사실 필자가 공부를 하면서 가장 궁금했던 부분이라 따로 다루고 싶었다. 특히 Pooling Layer에 대한 포스터를 만들 때 많은 의문이 들었다. Pooling Layer를 사용하면 parameter의 수를 줄이기 때문에 과적합을 방지할 수 있다고 한다. 대체 무슨 관계가 있는걸까?
복잡하게 생각할 필요가 없었다. 파라미터의 수가 많다는 것은 데이터에 대해 좀 더 ‘세세하게’ 학습을 할 수 있다는 것을 의미한다. 즉, 불필요한 부분까지 학습을 하게 되고 결론적으로 ‘암기’가 되어버리는 것이다.
예를 들어 이미지 데이터 안에 ‘댕댕이’의 유무를 구별하는 모델이 있다고 하자. 만약 복잡한 모델로 학습을 하게 되면 이미지 속 ‘댕댕이’의 고유한 특징을 잡아낼 뿐만 아니라 ‘댕댕이’를 제외한 주변 ‘노이즈’까지 전부 학습을 하게 된다. 그러면 결국 ‘댕댕이’가 없는 이미지인데도 불구하고 주변 ‘노이즈’를 인식해서 ‘댕댕이’가 있다고 예측하는 경우가 생긴다. 결국 ‘댕댕이’를 구별했다기 보다는 ‘학습 데이터’ 자체의 특징을 잡아내서 학습을 한 결과가 나온 것이다.
과적합 탐지
학습 도중에 과적합이 발생했다는 것을 어떻게 알 수 있을까? 가장 좋은 방법은 학습 데이터를 Train과 Validation로 나눠서 각각의 Loss를 확인하는 것이다.
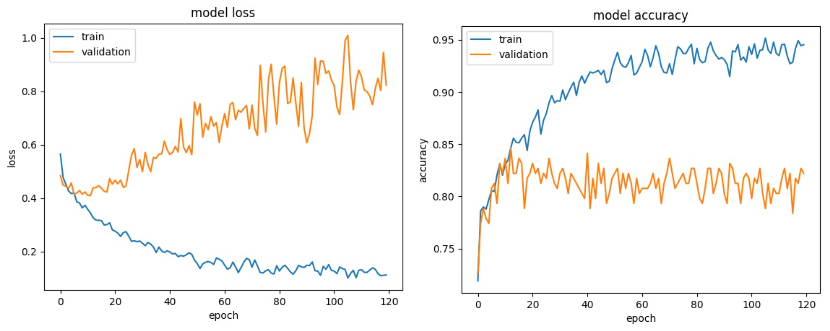
위 Loss의 그래프처럼 Train과 Validation을 비교했을 때 Train의 loss는 감소하고 있는 반면 Validation의 Loss가 증가하는 추세가 보이면 overfitting이 되었다고 볼 수 있다. 학습 데이터에 대해서는 잘 작동하지만, 새로운 데이터에 대해서는 작동하지 못하는 전형적인 현상이다.
과적합 방지
과적합을 방지하는 테크닉은 다음과 같다.
- 데이터의 양 늘리기(Train with more data)
- 모델의 복잡도 줄이기
- Regularization(정규화, 일반화)
- Drop out 사용
- Early Stopping
데이터의 양 늘리기
학습데이터의 양이 상대적으로 적을 경우, 모델이 학습을 하는 과정에서 같은 데이터를 여러 번 학습을 하게 된다. 그러면 결국 분류하고자 하는 특정 물체의 고유한 특징을 찾아내는 것 보다는 이미지 자체의 패턴을 ‘암기’해버린다. 따라서 데이터의 양을 증가시켜서 좀 더 일반적인 패턴을 배울 수 있도록 해야한다. 데이터를 추가로 더 수집하거나 인위적으로 데이터를 변형시키는 Augemtation기법을 활용할 수도 있다. 주의할 점은 딥러닝의 명제 중 하나인 ‘쓰레기가 들어가면 쓰레기가 나온다’에 비춰볼 때 반드시 전처리가 된 데이터를 추가해줘야한다.
(똥쓰레기 데이터가 추가되면 의미가 없다. 더 안 좋아질텐데~)
모델의 복합도 줄이기
위에서도 얘기했듯이 모델이 복잡해지면 그만큼 학습해야 하는 파라미터(가중치)가 많아져서 과적합을 야기한다. 따라서 파라미터의 주된 범인인 Fully-connected Layer를 줄이거나 Pooling Layer를 사용하는 등 다양한 방법을 통해서 은닉층(Hidden Layer)을 줄이면 과적합을 방지할 수 있다.
(사실 밑에 나올 Regularization을 하는 이유와 동일하다.)
Regularization(정규화, 일반화)
영어를 해석하면 ‘정규화’가 되지만, 의미로는 ‘일반화’에 더 가깝기 때문에 두 단어를 혼용해서 사용한다. 기계학습에서 모델 $h(x)$은 Loss Function $J(\theta)$ 의 값이 최소가 되도록 하는 방향으로 학습이 진행된다.
- $h(x)$ : 모델
- L2 : L2 Regularization
- $\theta$ : 가중치(파라미터)
- $\lambda$ : 정규화 변수, 정규화의 강도 설정(하이퍼 파라미터)
- $J(\theta)$ : 손실함수
손실함수를 최소로 하는 방향으로 학습을 진행하지만, 동시에 L2 Regularization 식에 있는 $\theta$값도 최소가 되는 방향으로 학습을 진행한다. 즉, MSE는 계산이 된 후에 나온 값(loss)에 대해 최소가 되는 $\theta$가 결정된다면, L2는 $\theta$ 자체의 값을 최소로 하는 방향으로 학습을 한다. 두 가지 모두 만족시키는 것이 최종 목표이다.
단순히 Loss Function(MSE)에만 의존해서 낮아지는 방향으로 진행이 되면 특정 가중치값이 증가해서 오히려 나쁜 결과를 야기시킬 때도 있다. 특정 가중치값이 증가한다는 뜻은 결국 모델의 복잡도를 증가시키는 것과 같기 때문이다. 따라서 모델 복잡도 증가를 방지하기 위해 정규화 기법을 사용하는 것이다.
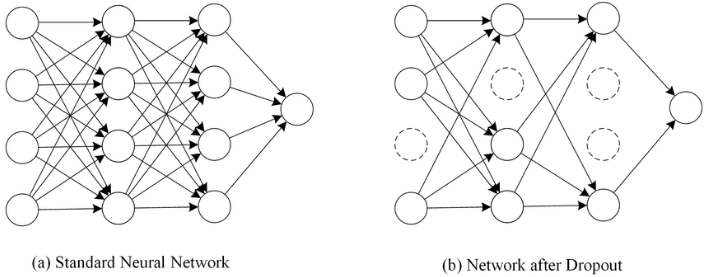
Drop out
Drop Out 기법은 모델이 학습하는 과정에서 몇 개의 노드(가중치가 계산되고 난 후)를 강제로 랜덤하게 0값으로 만드는 기법이다. 인공신경망이 특정 뉴런에서 너무 의존적이게 되는 것을 막아주고 항상 다른 뉴런들의 값이 0으로 변하기 때문에 다양한 모델을 사용하는 앙상블 기법이 되는 것 처럼 효과를 만들어 과적합을 방지할 수 있다.
Early Stopping
모델을 학습하는 과정에서 train Loss와 Test Loss가 감소하는 양상을 보면서 과적합이 발생하기 시작하는 지점에서 학습을 멈추는 기법을 말한다. 해당 지점부터는 또 다른 방법을 이용해 학습을 하거나 Learning Rate를 조절하는 등 마치 Generalization을 하는 것 같은 효과를 줄 수 있다.
지금까지 과적합에 대해 알아보았고 방지할 수 있는 방법에 대해 알아보았다. Loss를 낮추기 위해 계속해서 학습을 하다보면 모델이 ‘학습’을 하는 것 보다는 ‘암기’를 하게 되는 시점이 생긴다. 따라서 이러한 현상을 방지하기 위해 미리 알고 있는 것이 좋을 것 같다.