이번 포스터에서는 인공신경망 분야 중 하나인 ComputerVision의 기본이 되는 알고리즘인 “Convolutional Neural Network”에 대해 알아볼 것이다. CNN의 개념은 다른 분야에서도 많이 사용되고 있긴 하지만 이미지와 관련된 분야에서 획기적인 발전이 이루어졌다. CNN이 무엇인지 알아보고 Pytorch로 어떻게 구현하는지에 대해서도 다뤄보자.
이미지 필터링(Filtering)
사진을 찍고 편집을 해 본 경험은 누구나 다 있을 것이다. 얼굴에 잡티를 제거하거 좀 더 예쁘고 잘생기게 만들기 위해 턱을 깍고, 피부의 톤을 바꾸는 등이 있다. 사실은 이 작업들은 모두 ‘필터(Filter)`에 의해 작동이 된다. 필터링이란 필터를 이용해 이미지를 이루고 있는 픽셀행렬에 여러가지 수식을 대입해 다른값으로 바꿔서 이미지를 변형하는 것을 말한다. 주로 잡티를 제거할 때 가장 많이 사용을 하는 필터인 블러(blur) 필터로 예를 들어보자.

위 사진은 Blur Filter를 사용한 결과이다. 이미지를 흐릿하게 만들어서 각중 노이즈를 제거하는 용도로 많이 사용된다. 이 필터를 사용자가 원하는 부위에 적용을 하면 잡티제거가 된다.
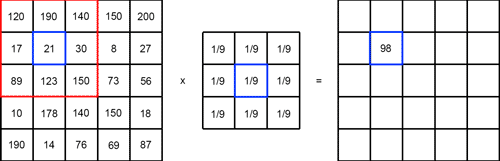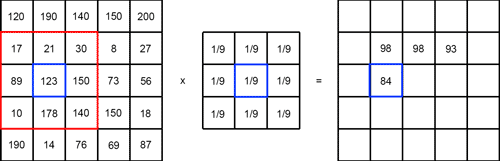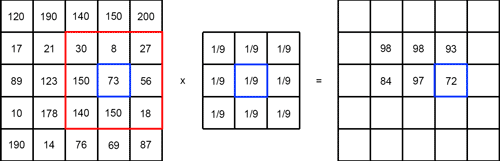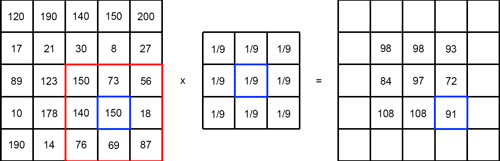
필터가 적용되는 방식은 다음과 같다.
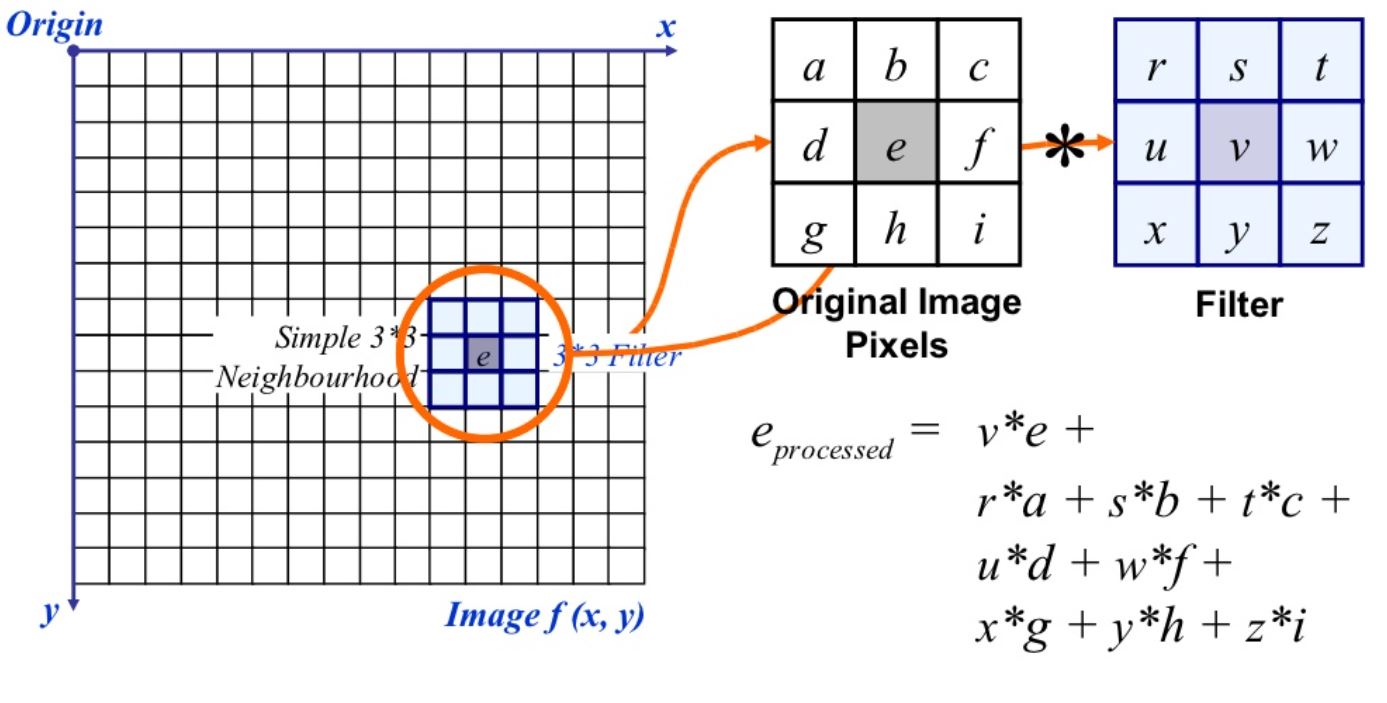
위 사진은 3x3핕터가 이미지에 적용되는 모습이다. 이미지 픽설 위치에 각각 대응하는 필터의 값을 곱한 후 모두 더한다. 3x3필터는 총 9개의 값으로 구성되어 있기 때문에 이미지 픽셀의 9개 구역에 각각 대응하여 곱한 후 더한다. 필터는 옆으로 움직이면서 위와 같은 계산을 반복한다.
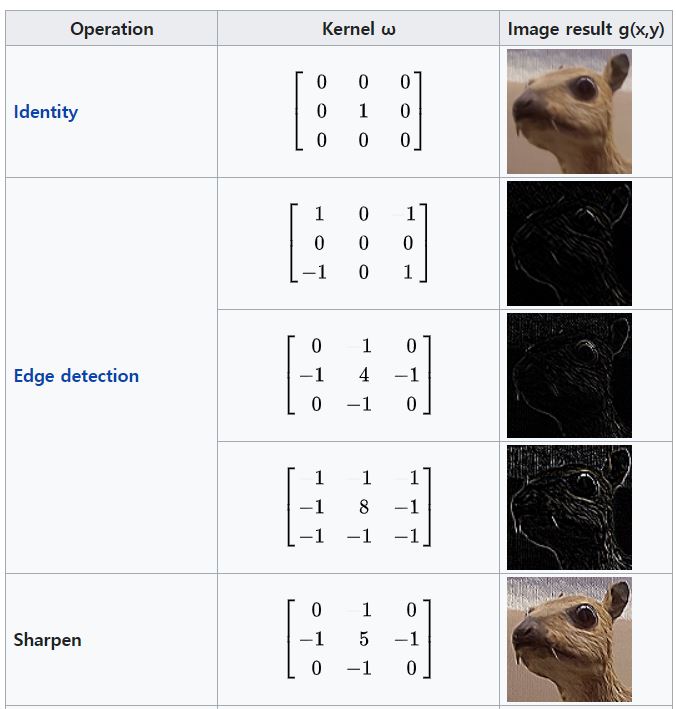
필터링을 통해 한 이미지를 다양하게 변환할 수 있고 상황에 알맞는 필터를 사용해 여러가지 정보들을 추출할 수 있다. 필터의 종류는 다음과 같다.
합성곱 신경망(Convolutional Neural Network, CNN)
위에서 언급한 필터링 기법을 인공신경망에 적용한 알고리즘이 바로 CNN이다. 1989년 LeCun에 의해 발표된 논문인 “Backpropagation applied to handwritten zip code recognition”에서 처음 소개되었고 이후에 2003년 Behnke이 작성한 “Hierarchical Neural Networks for Image Interpretation”을 통해 일반화되었다. CNN의 핵심은 이미지의 공간정보를 유지한다는 것이다. 즉, 이미지 내에 물체가 있다고 할 때 그 물체의 ‘모양’에 대한 정보를 추출할 수 있다는 뜻이다.
CNN의 구조
CNN은 크게 3단계로 구성되어 있다.
- 이미지의 특징(정보)를 추출하는 단계(Convolution Layer)
- 이미지를 축소하거나 ‘공간정보’를 유지해주는 단계(Pooling Layer)
- feature map 조합 및 분류하는 단계(Fully-connected Layer)
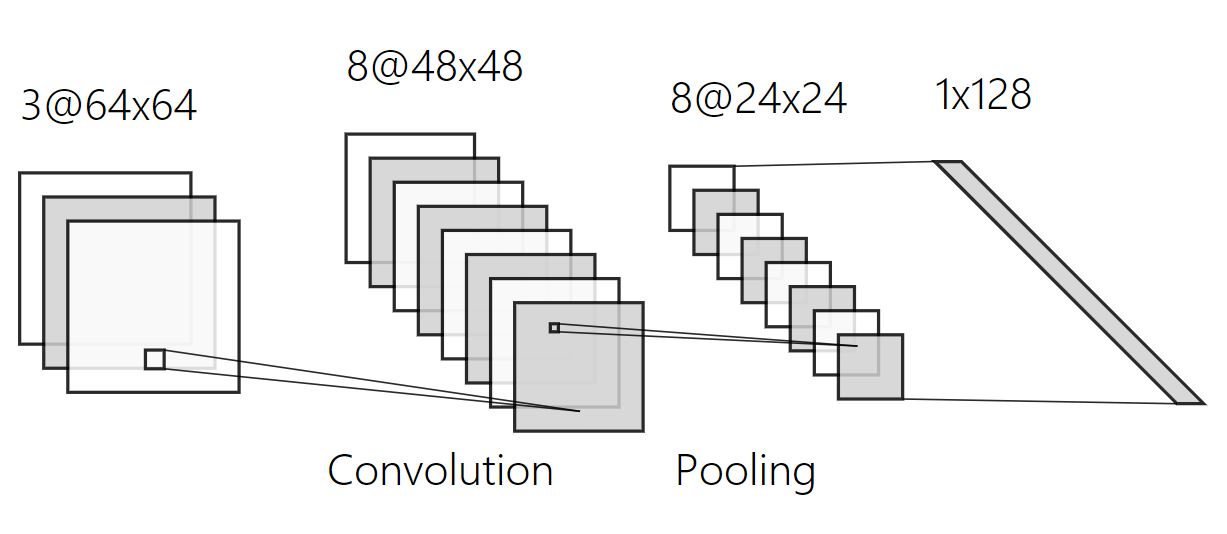
1. 합성곱 계층(Convolution Layer)
이미지에 필터링 기법을 적용해 여러가지의 특징을 추출하는 층이다. 핕터가 이미지에 적용되는 것과 계산방식이 동일하다. 다민 위에서 언급한 필터는 1x3x3(Channel, Width, Height)이었지만 Convolution Layer는 입력값의 의해 Channel수가 결정된다. 위 사진처럼 입력값이 RGB채널을 가진 이미지라면 입력값의 크기는 3@64x64(=3x64x64)이 되고, 이에 따라 filter의 크기는 3 x H x W가 된다. 여기서 H와 W는 모델 설계자가 정하는 값이다.
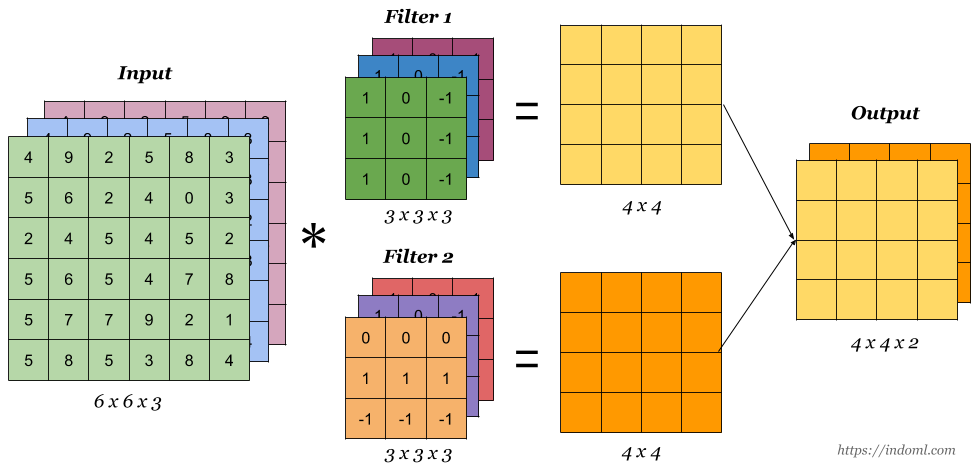
Input의 channel수가 동일하게 Filter1의 channel도 3이다. 사진(3)에서 표현되는 계산방식과 동일하지만, 3개의 채널이 동시에 계산이 된다. 이 부분이 필자도 처음에 이해가 잘 안 되는 부분이었지만, filter 1개가 3개의 channel을 가지고 있고, 결과가 1개의 channel로 나오기 위해서는 어떻게 계산이 되는지 생각해보면 이해하기 편하다.
Convolution Layer는 이미지의 특징을 추출하는 단계이다. 여러가지의 Filter를 이용하면 아래 그림과 같이 다양한 특징들을 추출할 수 있는데, 이와 같은 특징들을 Feature Map이라고 부른다. 인공신경망은 Feature map의 특징들을 이용해 학습을 한다.

Convolution Layer의 특징은 다음과 같다.
- 이미지 픽셀의 ‘값’ 그 자체에 집중하기 보다는 각 픽셀값 주위의 관계에 많은 영향을 받는다.
- 따라서 이미지 내에 있는 물체의 ‘공간정보’에 대한 내용을 추출할 수 있다.
- 필터가 스스로 학습하기 때문에 다양한 종류의 필터를 얻을 수 있다.
Convolution Layer 학습
기계학습은 스스로 학습하는 것을 말하는데, Convolution Layer에서 학습이란 filter의 값을 조정하는 것이다. 사진(4)에 나와있는 필터의 종류는 사람이 직접 만들어낸 필터이기 때문에 각 값들이 변하지 않는다. 하지만 Convolution Layer는 오차역전파를 통해 필터값을 학습한다.
2. 풀링 계층(Pooling Layer)
Pooling Layer란 이미지의 크기를 축소(sub-sampling)하거나 이미지 내에 있는 물체들의 ‘공간정보’를 유지시켜주는 필터이다. 입력값은 주로 Feature map이고, 각 feature map으로부터 유용한 정보를 추출한다.
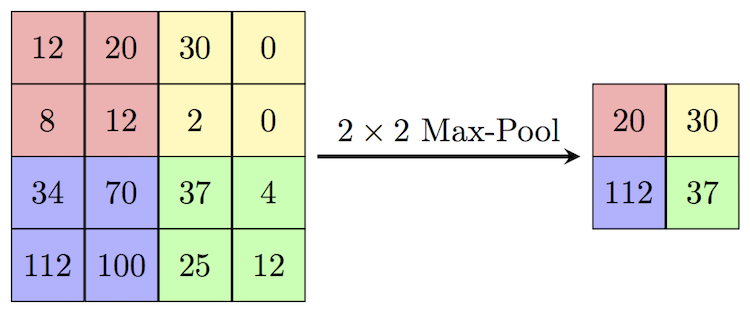
가장 대표적인 예로 Max-Pooling이 있는데, 필터의 ‘값’이 존재하지는 않고 필터에 대응하고 있는 픽셀값들 중 최대값을 뽑아내는 필터이다. Max-Pooling은 물체나 사람의 얼굴을 탐지할 때 주위 픽셀값의 분포와 다르게 유난히 튀는 픽셀값이 있을 때 가장 큰 효과를 볼 수 있다.
Pooling Layer의 특징은 다음과 같다.
- 이미지에 있는 물체가 이동하거나 회전해도 물체 고유의 특징을 잡아낼 수 있다.
- 이미지의 크기를 줄여서 연산량과 메모리, 학습 시간을 크게 절약할 수 있다.
3. Fully-connected Layer(Dense Layer)
Filter에 의해 추출된 Feature map을 조합하고 분류하는 부분이다. Fully-connnected란 말 그대로 빽빽히 연결되어 있다는 뜻으로 Dense Layer라고도 불린다. 선형회귀를 할 때 사용했던 Linear가 바로 Fully-connected layer이다.
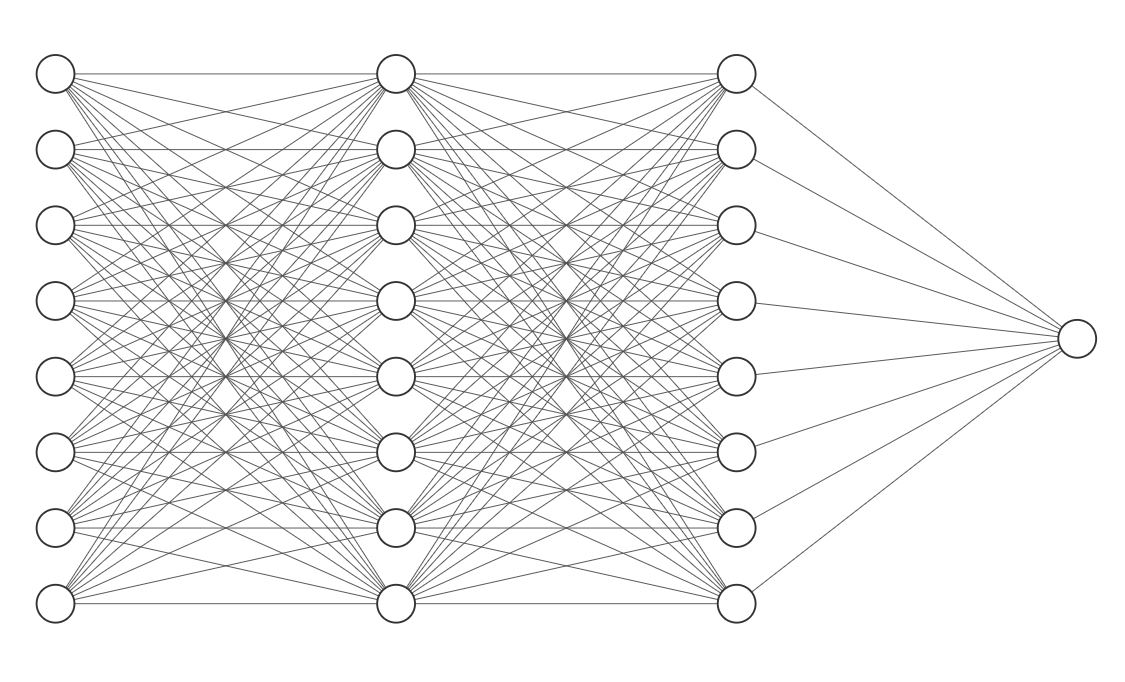
Dense Layer의 구조를 잘 보면 input이 1차원인 것을 알 수 있다. 하지만 방금까지 우리가 다뤘던 feature map은 2차원 행렬이다. 따라서 이 부분에서는 feature map을 1차원으로 나열한 뒤 연산을 실시한다. feature map 부분에서 충분한 특징들을 추출한 후에 그 특징들을 Dense Layer에서 조합을 하고, 최종적으로 결과값을 출력하게 되는 것이다.
Dense Layer의 특징은 다음과 같다.
- 마지막에 결과를 출력할 때 필요한 layer이다.
- 이름 그대로 너무 뺵뺵해서 계산해야 하는 파라미터의 수가 매우 많다.
- 2차원 행렬을 1차원으로 낮추기 때문에 막대한 정보의 손실이 발생한다.
CNN이 강력한 이유
CNN 알고리즘이 ComputerVision 분야에서 매우 강력해진 이유는 위에서 언급한 ‘공간정보’의 유지 때문이다. CNN 알고리즘을 사용하기 전에는 입력값이 모두 Linear처럼 1행이었기 때문에 이미지를 분류하는 알고리즘을 만들 때도 아래와 같이 모든 픽셀값을 펼쳐서 연산을 실시했다.
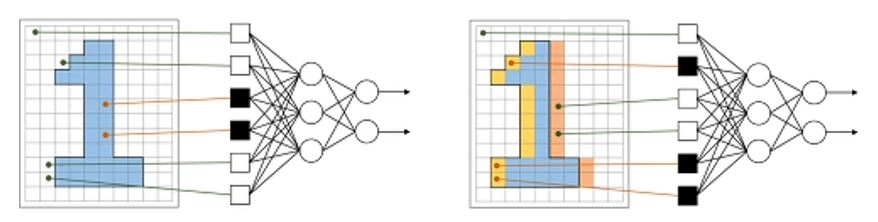
결국 이미지가 갖는 공간적 요소가 모두 파괴되어 성능이 좋지 않았다. 하지만 CNN 알고리즘은 이러한 문제점을 해결하였고, 모델의 성능을 비약적으로 향상시켰다.
Stride과 Padding
CNN는 Filter가 이미지 내부를 이동하면서 연산을 진행한다. 기본적으로 Filter가 이미지 내부를 이동할 때는 왼쪽 위에서부터 오른쪽으로 이동하면서 최종적으로는 오른쪽 아래에서 멈추게 된다.
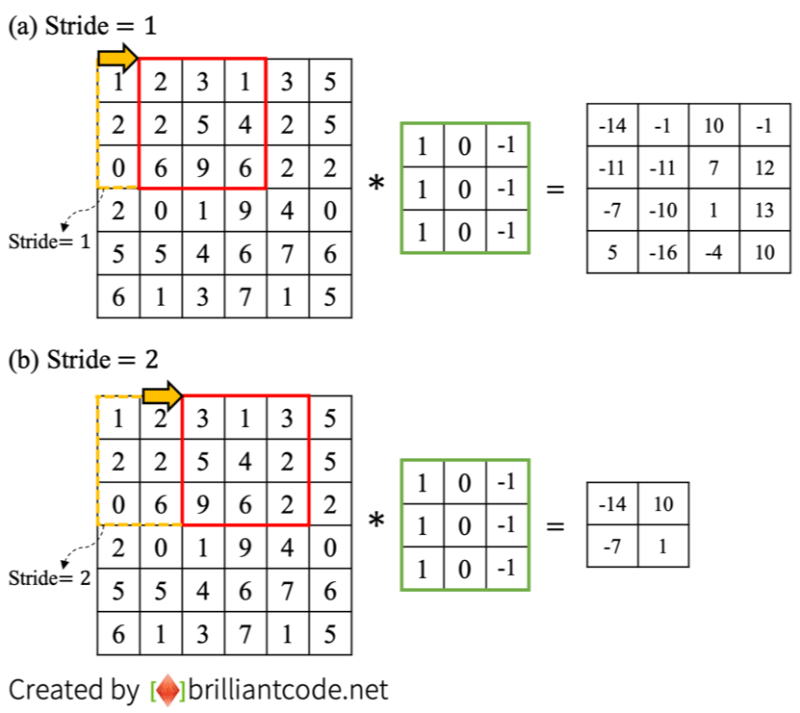
Stride
Filter가 이동할 때 몇 칸씩 이동할지 정해주는 값이다. 보통은 Stride을 1로 설정하여 filter가 1칸 씩 이동해 연산을 실시하지만, 연산의 효율을 높이거나 이미지의 크기를 줄이기 위해 다른 값으로 설정을 하기도 한다. 위에서 다뤘던 Max-Pooling Layer는 stride가 2인 Filter이다.
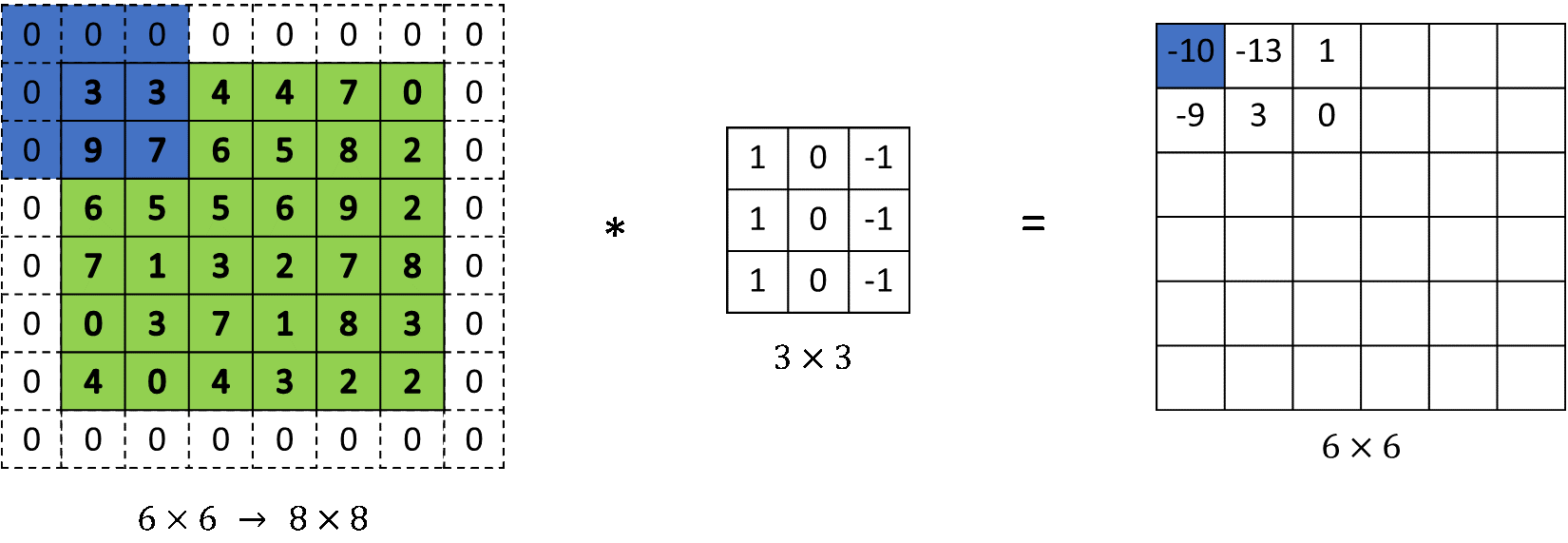
Padding
Filter가 연산되는 모양을 보면, 처음 입력값과 출력값의 크기가 달라진다. 필터가 적용되면 범위 안에 있는 픽셀값들의 합이 필터의 가운데 부분으로 합쳐진다. 필터가 이미지의 크기를 넘어서 갈 수 없기 때문에 가장자리 부분은 연산에 참여만 할 뿐, 그 부위에 필터를 적용할 수 없는 문제가 발생한다.
위에 같은 문제를 해결하기 위해 Padding효과를 적용한다. padding을 통해 이미지 가장자리 부분에 dummy값을 채워넣어 가장자리도 필터가 적용될 수 있도록 한다.
실제로 인공신경망 모델을 설계할 때 Stride와 Padding 요소를 잘 조합해 더 좋은 성능의 모델을 만들어낸다. 따라서 여러 실험을 통해 작절한 값을 정해주는 것도 매우 중요하다.
Pytorch 코드 실습
Convolution Layer
Pytorch에서는 nn.Conv2d()을 통해 2차원의 Convolution Layer를 제공한다.
import nn
con_layer = nn.Conv2d(in_channels = 1, out_channels = 20, kernel_size = 5, stride = 1, padding=1)
>>> print(con_layer)
# Conv2d(1, 20, kernel_size=(5, 5), stride=(1, 1))
con_weight = con_layer.weight
>>> print(con_weight.shape )
# torch.Size([20, 1, 5, 5])
# out_channel 20, filter_channel = 1, filter_size = 5x5
Conv2d(): 2차원 Convolution Layer, 주로 입력하는 옵션은 코드에 있는 것과 같다.con_wieght의 shape을 보면 (20, 1, 5, 5)인데, out_channel을 20으로 설정했기 때문에 필터의 채널의 개수도 20개이다.
임의의 이미지에 적용하면 다음과 같다.
from PIL import Image
import torch.nn as nn
transform = transforms.Compose([
transforms.ToTensor()
])
img = Image.open('../data/example.jpg')
img_trans = transform(img)
img_input = img_trans.unsqueeze(0)
>>> print(img_input.shape)
# torch.Size([1, 3, 295, 295]) # batch, channel, Height, Width
con_layer = nn.Conv2d(3, 10, 3, padding=1)
feature_map = con_layer(img_input)
>>> print(feature_map.shape)
# torch.Size([1, 10, 291, 291]) # batch, channel, Height, Width
feature_map0 = feature_map[0][0].detach()
>>> print(feature_map0.shape)
# torch.Size([295, 295])

transform: 이미지 전처리(Tensor로 변환)unsqueeze(x): x자리에 차원 1개를 추가한다.(3, 295, 295) -> (1, 3, 295, 295)detach():Conv2d()연산이 이루어지면 자동으로Autograd()이 실행되고 미분값이 계산되어 접근이 불가능한 상태가 되는데, 접근이 가능하도록 하는 함수
학습이 아직 안 되고 무작위로 초기화된 Convolution Layer로 feature map을 추출해봤다. 단순히 1개의 channel만 봐도 여러 특징들을 추출했다. 수많게의 feature map이 생기면 다양한 특징들이 추출될 것 같다.
Max-Pooling
Pytorch에서는 nn.MaxPool2d()을 통해 Max-Pooling Layer를 제공한다.
import torch.nn as nn
pool_layer = nn.MaxPool2d(2,2)
>>> print(pool_layer)
# MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
img_trans = transform(img)
feature_map = pool_layer(img_trans)
>>> print(feature_map.shape)
# torch.Size([3, 147, 147])

이번 포스터에서는 CNN의 개념과 구조, 특징에 대해 알아보았다. Computer Vision 분야에 있어서는 필수적으로 사용되는 알고리즘이기 때문에 많은 발전이 이루어지고 있다. CNN이 ‘공간정보’를 유지할 수 있어서 이미지에 많이 사용되지만, 자연어처리에서도 연산의 효율과 학습시간 단축을 위해 CNN을 사용하고 있다. 많이 보편화 된 만큼 자세히 알고 있으면 좋을 것 같다.