이번 포스트에서는 Pytorch를 이용하여 신경망을 정의하는 방법과 구조에 대해 알아보고 텐서(Tensor)가 어떻게 계산이 되는지, 또한 실제로 신경망이 어떻게 학습이 되는지에 대해 알아보자.
신경망 정의
아래의 코드는 Pytorch를 이용하여 신경망 모델을 정의할 때 사용하는 프로토타입이다.
import torch
import torch.nn as nn
class Model(nn.Module): # Pytorch 모듈 중 nn 상속받기(nn에 있는 기능 사용 가능)
def __init__(self, input_size, output_size): # 초기화 함수
def forward(self, x):
return out
Pytorch에서는 모델을 정의할 때 Class를 이용하고, nn.Module을 상속받아 여러가지 유용한 유틸을 활용한다.
__init__(): 모델을 구성하는 여러 파라미터들을 정의하는 부분forward(): 입력값에 대해 계산이 이루어지는 부분nn.Module: Pytorch에서 제공하는 신경망을 이루는데 유용한 유틸 모음
보통 신경망은 연산이 가능한 여러 층들이 쌓여서 만들어진 모델이다. 따라서 __init__에서 신경망을 구성할 때 사용하는 각 층을 정의하고, 입력값과 출력값의 크기 등을 설정한다. 임의의 데이터를 생성하고 모델을 정의한 후 데이터에 맞는 선형회귀선을 찾아보자. 이때 학습하는 과정도 같이 알아보도록 하자.
필자가 정의하고 학습할 선형회귀모델은 다음과 같다.
데이터 생성
단순선형회귀를 이용하기 때문에 독립변수$x$와 종속변수$y$가 각각 1개이며 예측해야 하는 값은 2개이다. 임의의 데이터를 생성하면 다음과 같다.
x = torch.randn((100,1))
y = 7*x + 5 + torch.normal(0,2,(100,1)) # 노이즈 첨가
>>> torch.cat((x,y),1)[:10]
# tensor([[ 1.5048, 13.6858],
# [-0.1398, 5.4163],
# [ 2.3057, 22.8123],
# [ 0.5640, 7.9670],
# [-0.8410, -2.1296],
# [-0.1577, 1.7757],
# [ 2.9104, 24.8814],
# [-0.4915, -1.7805],
# [ 1.6042, 17.8675],
# [-1.1555, -6.8106]])
임의의 데이터를 생성할 때 이미 $\theta$값을 설정하였다. 하지만 선형회귀모델을 정의할 때 $\theta$값이 초기화되기 때문에 데이터에 맞는 $\theta$를 찾을 필요가 있다. 따라서 학습이 끝난 후에 예측된 $\theta$와 우리가 정했던 $\theta$가 일치하는 확인하면 될 것 같다. 다음과 같이 회귀선을 예측해야한다.
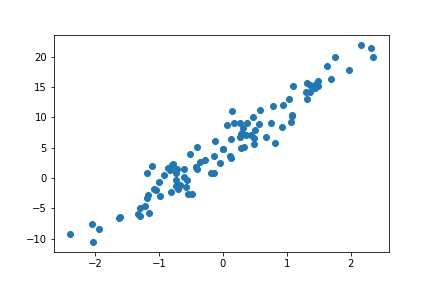
모델 생성
데이터를 생성했으니 이제 데이터를 학습할 모델을 정의해보자. Pytorch에서는 선형회귀모델을 정의할 수 있는 함수를 제공하는데, nn.Linear()을 이용하여 간단하게 모델을 생성할 수 있다.
import torch
import torch.nn as nn
class MyLinear(nn.Module): # Pytorch 모듈 중 nn 상속받기(nn에 있는 기능 사용 가능)
def __init__(self, input_size, output_size): # 초기화 함수
super(MyLinear, self).__init__()
self.linear = nn.Linear(input_size, output_size, bias=True) # nn모듈에 있는 Linear함수 사용하기
def forward(self, x):
y = self.linear(x) # x 연산하기
return y
model = MyLinear(1,1)
위 코드에 있는 정보들을 정리하면 다음과 같다.
nn.Module: Pytorch에서 모델을 정의할 때 여러 유틸을 제공super(): 아버지 클래스인nn.Module의__init__()함수를 호출한다는 뜻(덮어쓰기)nn.Linear(): 입,출력 크기에 맞는 선형회귀모델을 만들어주는 함수bias=True: 편향값을 설정(여기서는 $\theta_0$값을 의미)
모델을 정의했으니 잘 동작하는지 확인해보자. 추가로 기존 데이터와 생성된 모델로 예측한 데이터가 얼마나 이질적인지도 확인해보자!
with torch.no_grad(): # Autograd 끄기
model = MyLinear(1,1)
out = model(x)
>>>print(out[:10])
# tensor([[-0.3884],
# [ 0.1694],
# [-0.0855],
# [ 0.8922],
# [-0.5119],
# [-0.1453],
# [ 0.6156],
# [-0.0888],
# [-0.2215],
# [-0.2758]])
위 코드에서 진행한 계산은 단순히 확인용이기 때문에 torch.no_grad()을 통해 자동미분을 off한 상태로 실행을 했다. 실제와 예측 데이터를 비교하면 다음과 같다.
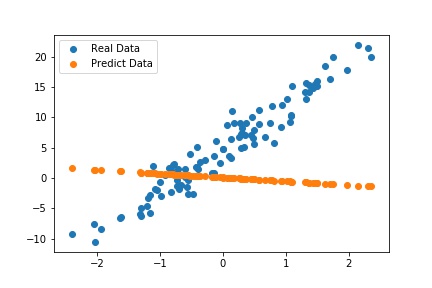
현재 초기화 된 $\theta$값을 확인하면 다음과 같다.
for p in model.parameters():
>>> print(p)
# Parameter containing:
# tensor([[-0.6244]], requires_grad=True)
# Parameter containing:
# tensor([0.0785], requires_grad=True)
nn.Linear()은 매개변수를 연속균동분포인 kaiming_uniform_을 사용하여 초기화한다. He initialization으로도 알려진 이 랜덤함수는 “Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification” - He, K. 이라는 논문에서 소개되었다. 기회가 되면 다뤄보도록 하겠다.
데이터를 생성할 당시에 설정한 $\theta$는 각각 다음과 같다.
지금부터는 모델이 위와 같은 $\theta$값을 가질 수 있도록 학습을 실시해보자.
학습(Training)
신경망이 학습을 하기 위해서는 학습할 ‘모델’이 필요하고, 실제 값과 예측값의 오차를 구해줄 ‘오차함수’(=손실함수)와 오차를 이용해 매개변수를 갱신해줄 ‘최적화 알고리즘’이 필요하다. 각각을 정의하면 다음과 같다.(각각에 대해서도 나중에 다뤄볼 생각이다.)
import torch.optim as optim
import torch.nn as nn
loss_func = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.001)
EPOCH = 20
BATCH_SIZE = 10
MSELoss(): 회귀모델에서 가장 많이 사용되는 성능 측정 지표(평균제곱오차)SGD(): 최적화 알고리즘 중 하나로 확률적 경사하강법lr=0.001: 학습률을 뜻하고 최적화 알고리즘이 얼마나 매개변수를 갱신할지를 나타내는 수치 ` ‘BATCH_SIZE` : 한 번 학습을 할 때(오차값이 계산될 때) 사용하는 데이터 개수(= 연산이 이루어질 때 컴퓨터 메모리에 올리는 데이터 개수)EPOCH: 전체 데이터를 학습하는 횟수
100개의 데이터가 있으면 10개(BATCH_SIZE)씩 묶음으로 10번 학습(연산 및 오차값 계산)하는 과정을 1번(EPOCH) 반복
학습을 위한 모든 준비는 끝났다. 이제 모델을 학습해서 MSELoss()의 값이 최소가 되도록 하는 $\theta$값을 찾아보자.
학습 진행
for e in range(EPOCH):
epoch_loss = 0
batch = int(len(x) / BATCH_SIZE) # BATCH_SIZE로 묶었을 때 나오는 총 묶음의 개수 = 10
batch_start = 0 # 데이터를 1묶음씩 불러오기 위해 처음값 설정
for i in range(batch): # 묶음의 개수만큼 반복
x_data = x[batch_start:batch_start+BATCH_SIZE] # BATCH_SIZE만큼 x 데이터 불러오기
y_data = y[batch_start:batch_start+BATCH_SIZE] # bATCH_SIZE만큼 y 데이터 불러오기
optimizer.zero_grad() # Autograd가 계산 된 모든 것들을 0으로 초기화
output = model(x_data)
loss = loss_func(output, y_data) # 오차값 계산
loss.backward() # 계산 된 오차값으로 Autograd 실행(미분 값 계산)
optimizer.step() # 계산 된 미분값과 lr을 결합하여 매개변수 갱신
epoch_loss += loss/10
batch_start += BATCH_SIZE
print(epoch_loss) # EPOCH 마다 오차값 출력
학습이 되는 과정은 다음과 같다.
- batch 크기만큼 데이터를 불러오기
- Autograd가 적용 된 모든 파라미터 0으로 초기화
- model을 통해 예측 실시
- 예측된 결과와 정답을 비교하여 오차 계산
- 계산 된 오차로 미분값 계산(Autograd 실행)
- 미분값과 lr을 결합하여 매개변수 갱신
- EPOCH 만큼 반복
학습이 잘 진행되고 있는지 매 EPOCH 마다 오차의 합을 출력했더니 다음과 같았다.
# tensor(57.3058, grad_fn=<AddBackward0>)
# tensor(41.2604, grad_fn=<AddBackward0>)
# tensor(30.0514, grad_fn=<AddBackward0>)
# tensor(22.1966, grad_fn=<AddBackward0>)
# tensor(16.6747, grad_fn=<AddBackward0>)
# tensor(12.7807, grad_fn=<AddBackward0>)
# tensor(10.0258, grad_fn=<AddBackward0>)
# tensor(8.0708, grad_fn=<AddBackward0>)
# tensor(6.6791, grad_fn=<AddBackward0>)
# tensor(5.6855, grad_fn=<AddBackward0>)
# tensor(4.9739, grad_fn=<AddBackward0>)
# tensor(4.4629, grad_fn=<AddBackward0>)
# tensor(4.0950, grad_fn=<AddBackward0>)
# tensor(3.8294, grad_fn=<AddBackward0>)
# tensor(3.6372, grad_fn=<AddBackward0>)
# tensor(3.4978, grad_fn=<AddBackward0>)
# tensor(3.3965, grad_fn=<AddBackward0>)
# tensor(3.3227, grad_fn=<AddBackward0>)
# tensor(3.2689, grad_fn=<AddBackward0>)
# tensor(3.2296, grad_fn=<AddBackward0>)
오차값들이 EPOCH마다 줄어드는 것을 알 수 있다. 하지만 어느정도 줄어들었을 때 더이상 감소하지 않는데, 아마도 손실함수가 최소값 주위에 도달했기 때문인 것 같다. 하지만 여기서 오차값이 0이 되지는 않는데, 이것은 경사하강법으로 최소값을 구하는 방법이기 때문에 계속해서 기울기 방향으로 매개변수가 갱신되고 있는 것이다. (최소값 부분에서 왓다갔다)
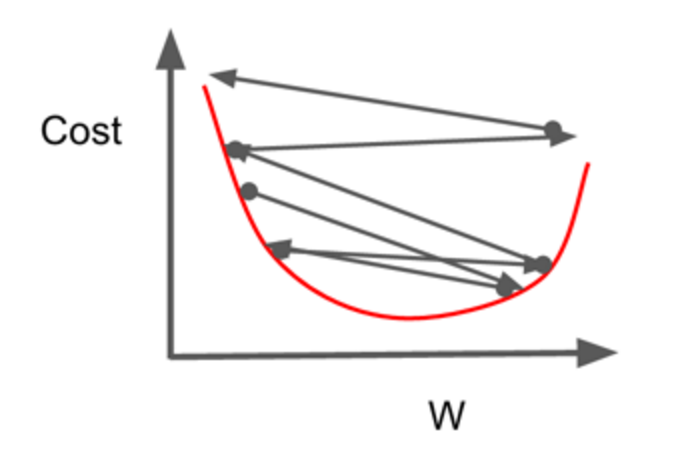
위와 같은 현상이 발생하면 작은 lr 값을 이용해서 오차값을 좀 더 작게 감소시켜 오차값을 최소부분으로 이동할 수 있도록 해야한다.
자 그럼 실제값과 예측값의 데이터를 비교해보자.
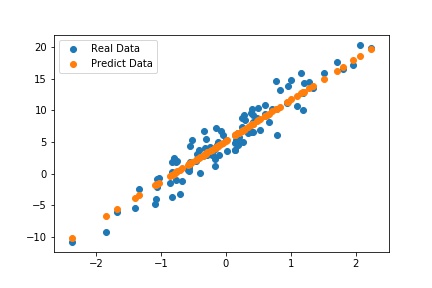
예측된 데이터를 보니 대부분이 회귀선 위에 있는 것을 알 수 있다. 즉, 최초 데이터에 대해 회귀선을 잘 구한 것 같다. 그렇다면 처음에 설정했던 매개변수와 동일한지 확인해보면 다음과 같다.
# Parameters 확인하기
for p in model.parameters():
>>> print(p)
# Parameter containing:
# tensor([[6.4488]], requires_grad=True)
# Parameter containing:
# tensor([5.1844], requires_grad=True)
수치로 비교해보면 다음과 같다.
\[\theta_0 = 5, \quad \theta_1 = 7 \rightarrow \theta_0 = 5.1844, \quad \theta_4 = 6.4488\]학습하는 과정의 전체 코드는 다음과 같다.
import torch
import torch.nn as nn
import torch.optim as optim
# Data 생성
x = torch.randn((100,1))
y = 7*x + 5 + torch.normal(0,2,(100,1)) # 노이즈 첨가
# Model 정의
class MyLinear(nn.Module): # Pytorch 모듈 중 nn 상속받기(nn에 있는 기능 사용 가능)
def __init__(self, input_size, output_size): # 초기화 함수
super(MyLinear, self).__init__()
self.linear = nn.Linear(input_size, output_size, bias=True) # nn모듈에 있는 Linear함수 사용하기
def forward(self, x):
y = self.linear(x) # x 연산하기
return y
# 모델 생성
model = MyLinear(1,1)
# 손실함수 및 최적화함수 설정
loss_func = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.001)
EPOCH = 20
BATCH_SIZE = 10
# 학습 진행
for e in range(EPOCH):
epoch_loss = 0
batch = int(len(x) / BATCH_SIZE) # BATCH_SIZE로 묶었을 때 나오는 총 묶음의 개수 = 10
batch_start = 0 # 데이터를 1묶음씩 불러오기 위해 처음값 설정
for i in range(batch): # 묶음의 개수만큼 반복
x_data = x[batch_start:batch_start+BATCH_SIZE] # BATCH_SIZE만큼 x 데이터 불러오기
y_data = y[batch_start:batch_start+BATCH_SIZE] # bATCH_SIZE만큼 y 데이터 불러오기
optimizer.zero_grad() # Autograd가 계산 된 모든 것들을 0으로 초기화
output = model(x_data)
loss = loss_func(output, y_data) # 오차값 계산
loss.backward() # 계산 된 오차값으로 Autograd 실행(미분 값 계산)
optimizer.step() # 계산 된 미분값과 lr을 결합하여 매개변수 갱신
epoch_loss += loss/10
batch_start += BATCH_SIZE
print(epoch_loss) # EPOCH 마다 오차값 출력
# 파라미터 확인
for p in model.parameters():
>>> print(p)
완전 일치하지는 않지만 그래도 노이즈가 포함된 데이터로 생각했을 때 비슷하게 예측한 것 같다. 앞 포스터에서는 ‘두 좌표를 이용한 방법’과 ‘정규방정식’을 이용하여 매개변수를 예측했는데, ‘경사하강법’ 또한 하나의 방법이 될 수 있다는 것을 알았다. 이것만 보면 사실 ‘경사하강법’은 너무 복잡해 보이지만, 모델이 깊어지고 매개변수들이 많아지면 ‘경사하강법’으로 최적의 매개변수를 찾는 것이 가장 간단하고 빠르다는 것을 알 수 있다. 기회가 된다면 더 복잡한 모델을 이용하여 학습을 하는 프로젝트를 진행해보기로 하자.